IMAGEBIND and PandaGPT简介
IMAGEBIND
先前的多模态对齐研究主要关注单个模态对的对齐,例如 (image, text), (video, audio), (audio, text)等,其嵌入空间局限于训练所用的模态对,例如(video, audio)嵌入不能直接用于text-based任务
学习真正的多模态联合嵌入空间的主要难点是缺少所有模态同时出现的高质量数据集
直觉上,图像可以自然地与许多模态绑定(bind),因此该论文的动机是利用多种image-paired数据,将各种模态嵌入分别与图像嵌入对齐,从而绕开缺少模态对齐数据的限制,学得一个联合嵌入空间

论文利用了已有的大规模image-text pair数据,并收集了4种与image/video自然成对的“自监督”数据——audio, depth, thermal, IMU
通过将5种modality embedding分别与image embedding对齐,实现这些模态之间的相互对齐
记image-paired模态对为$(I,M)$,$I_i,M_i$的嵌入分别为$q_i=f(I_i),k_i=g(M_i)$,训练方法就是简单的对比损失
实际中使用其对称版本$L=L{I,M}+L{M,I}$
虽然训练只使用了$(I,M_1)$和$(I,M_2)$,但zero-shot实验中可以观察到$(M_1,M_2)$的对齐
以下是一些模型细节
text encoder使用CLIP
image/video encoder使用同一个ViT,视频从2s中采样2帧,ViT的投影层使用类似I3D的时序膨胀(temporal inflation)
audio encoder也使用ViT (patch 16, stride 10),16kHz采样的2s音频,处理为128 mel频谱
thermal/depth image视为单通道图,使用ViT编码
IMU encoder使用Transformer,使用5s IMU片段采样2k timestep,通过1D卷积预投影
PandaGPT
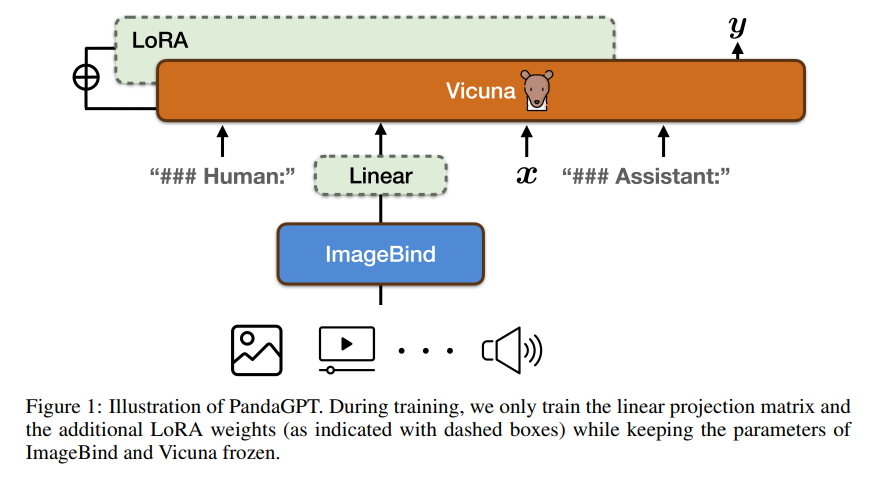
IMAGEBIND实现的只是多模态联合嵌入的学习,PandaGPT的目的是利用IMAGEBIND实现6种模态的instruction-following task
其思想很简单,在ImageBind和LM (Vicuna) 之间加入一个投影层,并利用LoRA加入微调权值,训练任务就是语言建模