
LLaVA论文解读
Liu H, Li C, Wu Q, et al. Visual instruction tuning[J]. arXiv preprint arXiv:2304.08485, 2023.
instruction tuning显著提升了LLM的zero-shot能力,但在多模态领域还没有相关研究,该论文的主要贡献有
- 创建了多模态的instruction-following数据集
- 构造了新的多模态大模型LLaVA (Large Language and Vision Assistant)
- 数据集和模型全部开源
Dataset
虽然多模态数据集在近几年不断涌现,但多模态instruction-following data仍很少
对于已有的image-caption pair $(X_v,X_c)$,创建instruction-following data最简单的方法是:制作一系列用于指示模型生成图像描述的提问$X_q$,然后将原样本扩展为Human:XqXv<STOP>\n Assistant:Xc<STOP>\n
然而这种简单的扩展缺乏多样性和深度推理
论文的做法是利用ChatGPT或GPT-4生成样本,具体的,将图像以Captions或Bounding boxes的形式作为条件输入GPT-4,结合特定的prompt,生成3种类型的instruction-following样本:Conversation、Detailed description和Complex reasoning

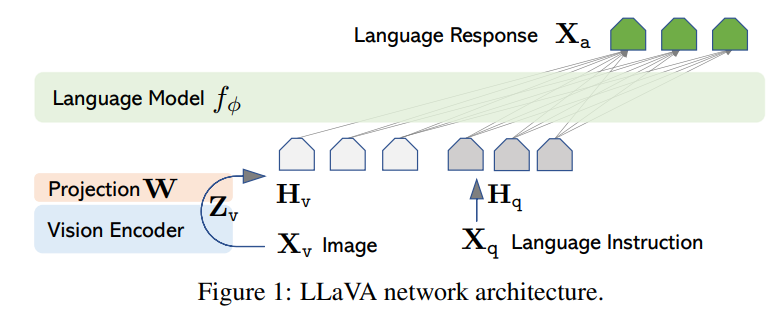
Model
LLaVA模型结构很简单,LM选择LLaMA,vision encoder选择CLIP
视觉特征经过一个投影层为visual token,使其与text token维度相同
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.