
Flamingo论文解读
Flamingo模型可以被视为多模态领域的GPT-3 moment,其论文是使用vision-language大模型进行few-shot/zero-shot learning的开创性研究
Method
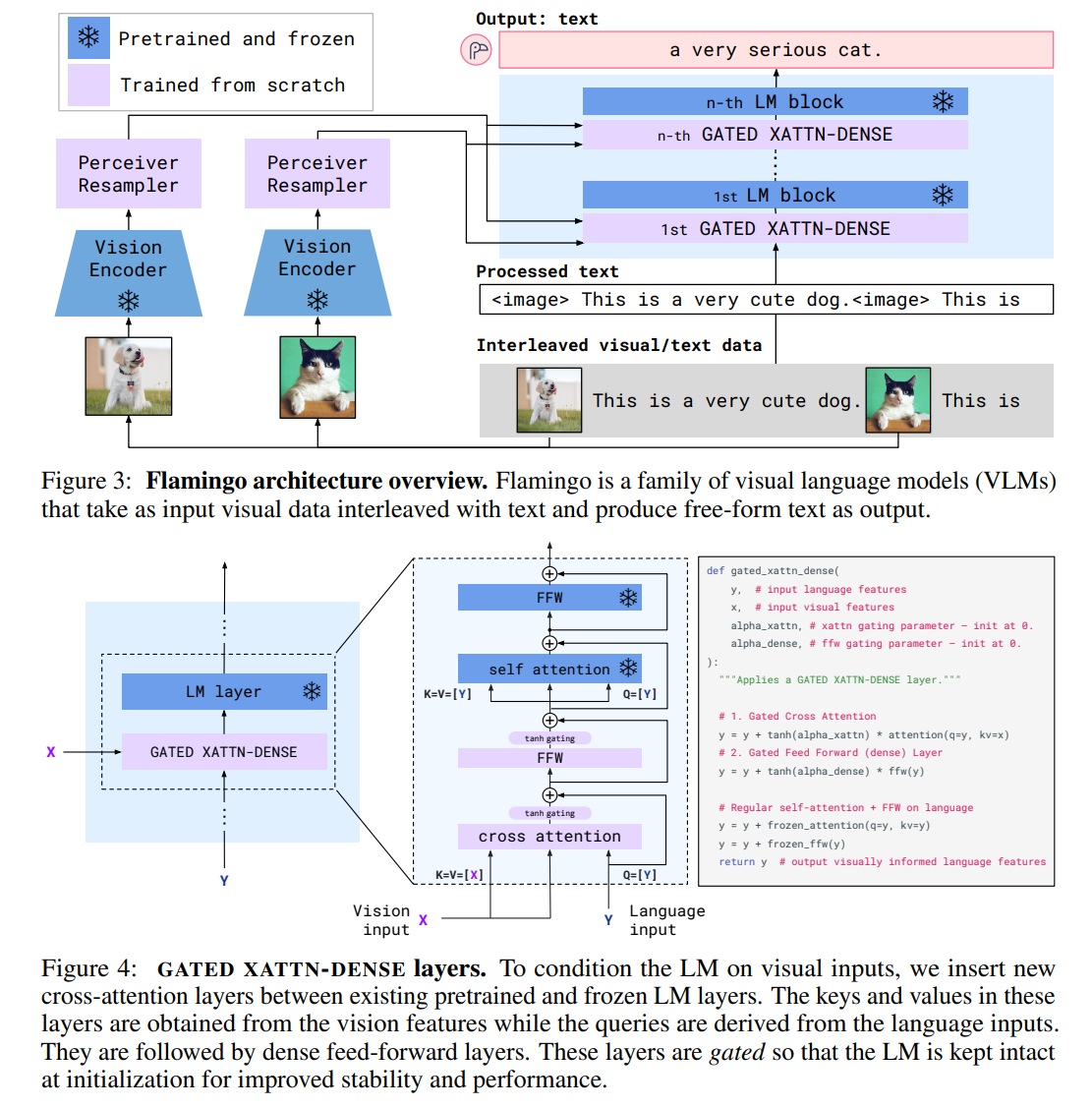
Flamingo模型整体结构如图3所示
Vision Encoder是冻结的预训练NFNet-F6,预训练任务同CLIP
模型允许图像/视频任意组织在文本中,其中视频按1FPS采样为图像序列
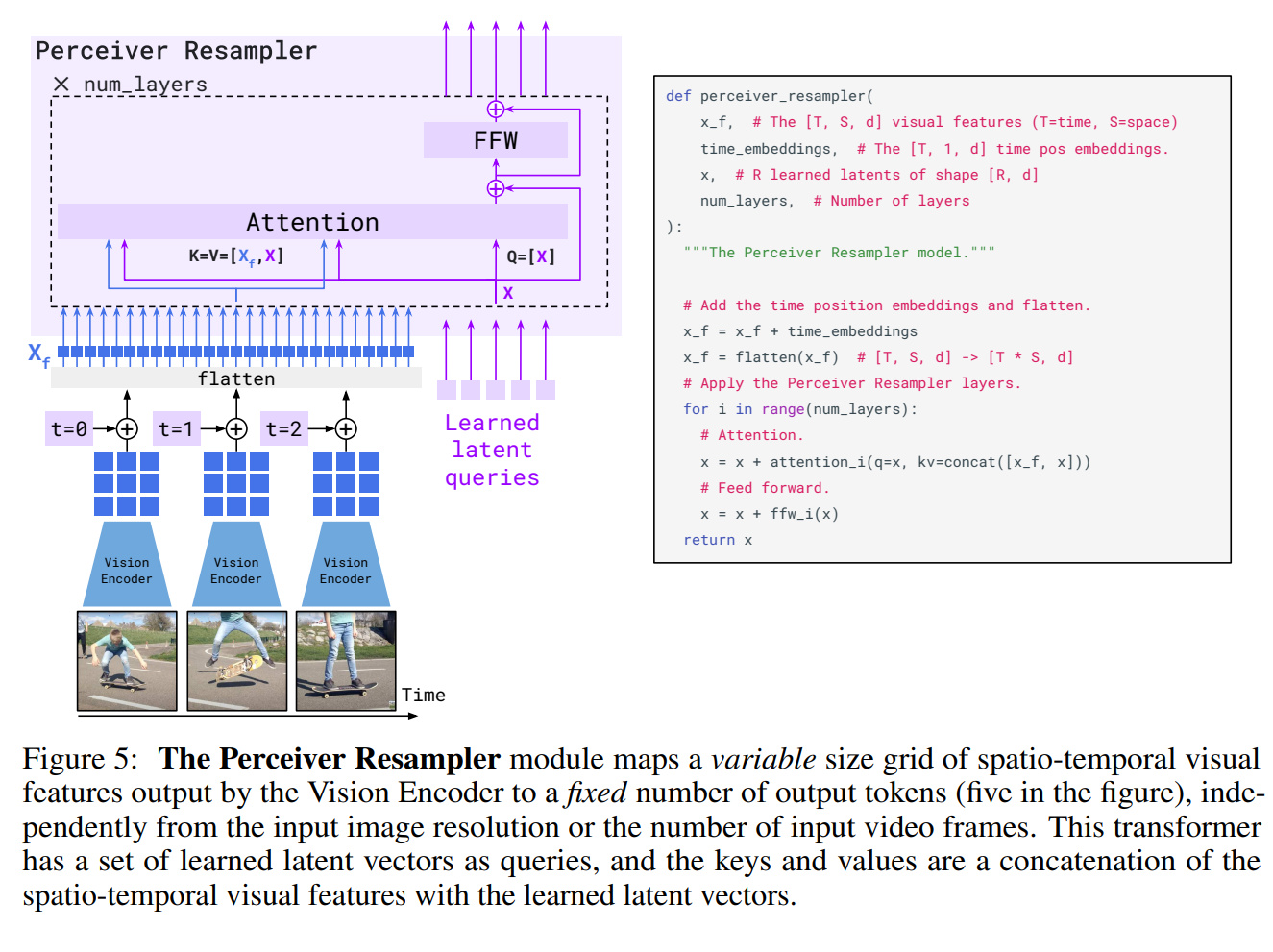
如图5所示,Perceiver Resampler是一个Transformer Encoder,其输入为一个特征图(图像)或加入temporal embedding的特征图序列(视频),以及一组可学习的latent queries(类似于BLIP-2),输出为一组固定大小的vision token
Perceiver Resampler可以这样理解:Vision Encoder的输出是2D特征图,其中每个pixel可视为一个提取的visual token,但由于输入图像分辨率不一,且往往很大,导致visual token过多,后续cross-attention计算量太大
因此Perceiver Resampler通过一组可学习的queries,在LM之前先对Vision Encoder编码的visual token使用attention,提取固定数量的、更稠密的visual token,再输入LM
LM使用冻结的预训练Chinchilla,这是一个decoder-only模型
如图4所示,每个LM block中插入一个gated cross-attention dense blocks,用于融合Perceiver Resampler提取的视觉特征,该block从头开始训练
在加入cross-attention的情况下,为了保证LM初始时仍能产生和原来一样的效果,其中加入了tanh-gating机制,它将cross-attention层的输出乘以tanh(𝛼)后再与residual connection相加,其中𝛼可学习,初始化为0
cross-attention层的mask比较特殊,每个text token只对之前最近的一个图像/视频进行attention
具体处理上,输入中所有图像/视频的位置由[image] token替代,text token根据其注意的图像分为多个chunk,由[BOS] token和[EOC] token分隔
虽然cross-attention中只关注到前面一个图像,LM中原self-attention层仍能捕捉到对前面所有图像的依赖

Flamingo模型使用从网络爬取的三类数据集混合训练
M3W: Interleaved image and text dataset:交错的文本和图像数据,从约43M个网页爬取,是训练模型few-shot能力的主要来源
Pairs of image/video and text:在ALIGN数据集基础上,收集新的LTIP (Long Text & Image Pairs)和VTP (Video & Text Pairs)数据集
其训练任务就是自回归式的语言建模
最后的实验结果就不详细说了,总之就是非常强大