
FlAN系列论文解读
FLAN
大语言模型(LLM),如GPT-3等,展现了很好的few-shot能力,但在zero-shot上表现并不好
一个可能的原因是,如果没有few-shot示例,模型很难处理与预训练数据格式不相近的prompt
一个直觉观点是NLP任务都可以通过自然语言指令(natural language instructions)描述,论文旨在利用这点提高预训练模型的zero-shot能力
论文提出了instruction tuning,其通过自然语言指令在60多个NLP数据集上微调,得到的模型称为Finetuned Language Net, FLAN
Method
论文通过将现有数据集转换为指令格式创建instruction tuning数据集
数据集包括62个文本数据集,按照任务类别分为12个集群
作者对其中每个数据集都人工制作10个不同的用自然语言指令描述任务的模板
此外对每个数据集还有不超过3个改变任务的指令模板,例如对情感分类任务,模板还包括要求语言模型生成评论
为了测试FLAN处理未见过的任务的能力,论文对unseen进行了保守定义——属于同一集群的数据集必须在训练时都未见过
论文使用的预训练模型是LaMDA-PT,一个137B的decoder-only模型
一般NLP任务可以分为分类和生成两类
对于生成,decoder-only的LaMDA-PT可以很自然的适应
对于分类,论文将特殊的OPTION token和所有输出类别token添加为输入的后缀,转换为生成任务
Experiments
如图所示是FLAN的zero-shot能力,具体的说明可以看论文
其中值得关注的是,对于能自然地用指令描述的任务(如NLI、QA、翻译等),instruction tuning非常有效,而对于许多语言建模任务(如常识推理、共指解析),instruction tuning不能带来提升
这一结果表明,当下游任务与原始语言建模预训练目标相同时(即指令很大程度上是冗余的情况下),instruction tuning是无用的
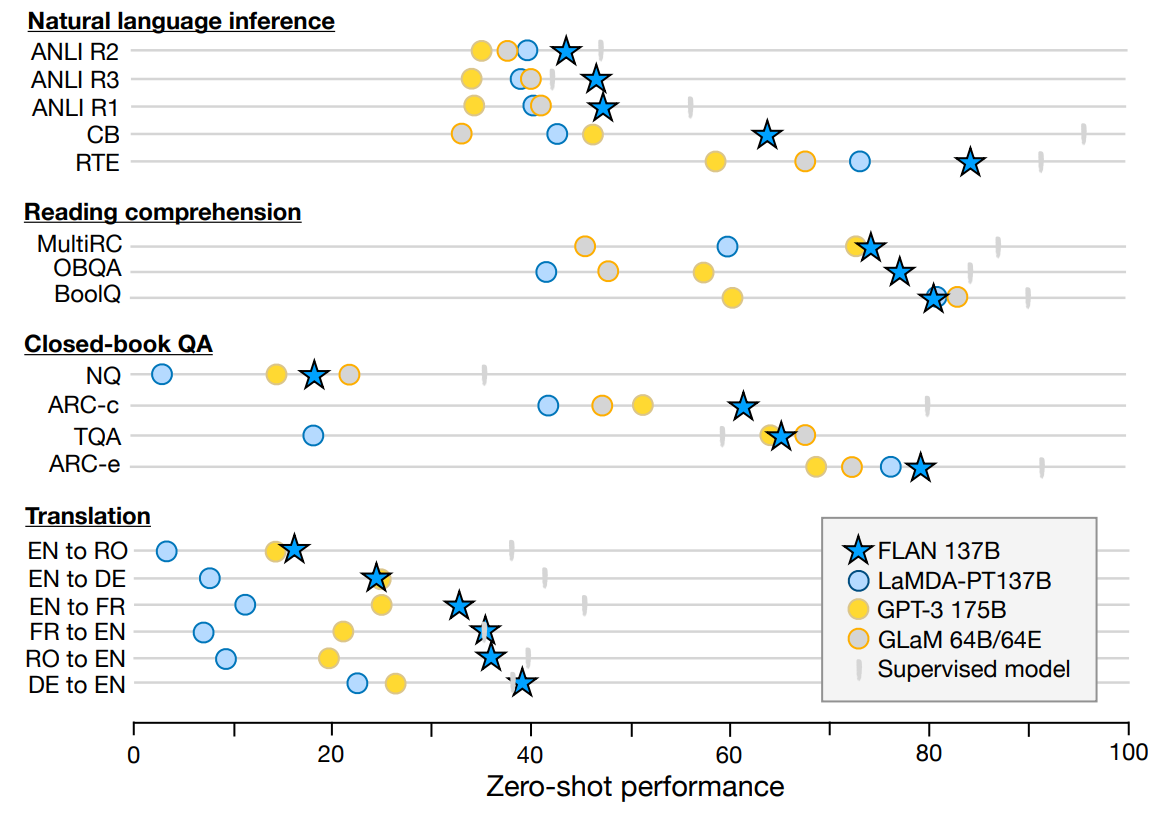
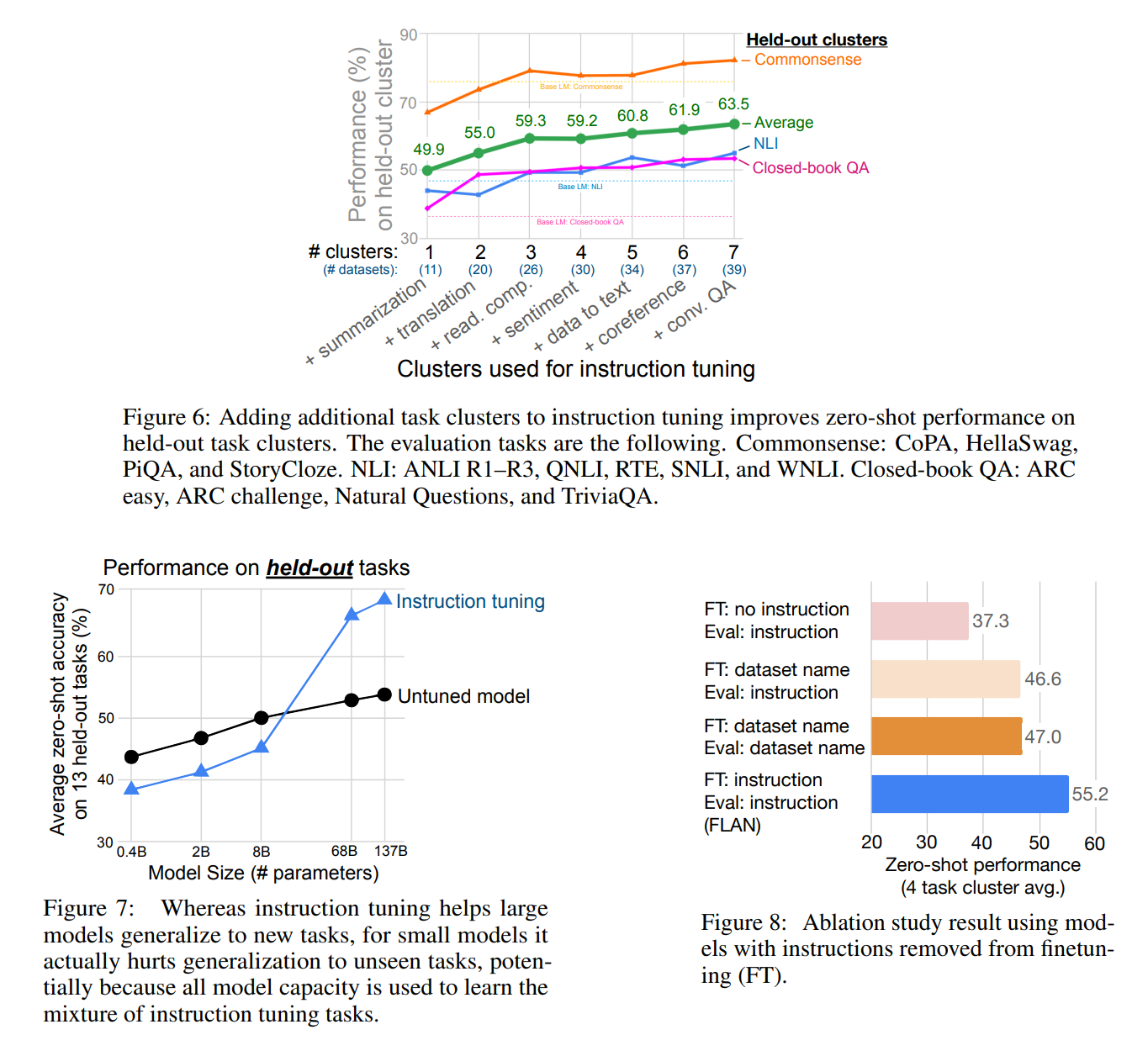
figure 6是训练数据量的消融实验,论文将NLI、closed-book QA和commonsense reasoning三个集群用于评价,剩余7个集群按所含数据集数量逐渐加入训练,由图可知模型性能随着数据量增大而不断提升,并且没有饱和的趋势
figure 7是模型规模实验,其中instruction tuning对100B量级的模型提升很明显,但8B以下的模型性能反而降低了,原因可能是微调训练的任务已经占满了其容量,没有更多的容量学习指令执行
figure 8是instruction tuning本身的消融实验,对微调/评价时是否使用instruction进行控制对比,图中dataset name表示在输入中加入数据集名字
论文还做了few-shot实验和soft prompt实验,结论都是性能有所提升,图可见论文
FLAN-T5/FLAN-PaLM
这篇论文研究了instruction tuning的规模提升,以及CoT对instruction tuning在推理任务上的影响
基于这两点研究,论文训练了FLan-PaLM和FLan-T5,实现了显著的性能提升
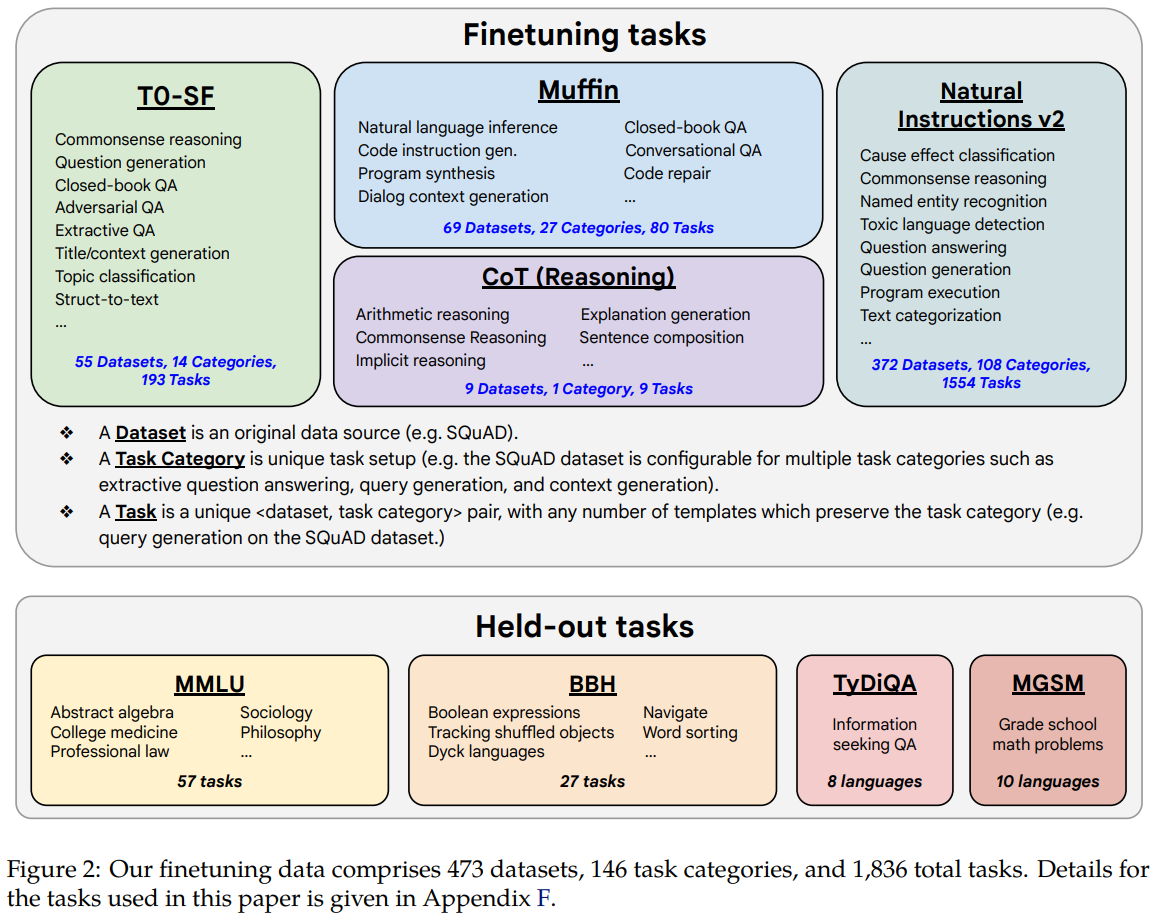
如图所示,论文从先前的研究中收集了包含1836个任务的数据集,此外还制作了一个包含9个数据集的CoT (chain-of-thought) 集合
具体的数据集和微调过程介绍可见论文,这里主要关注实验结果
Experiment
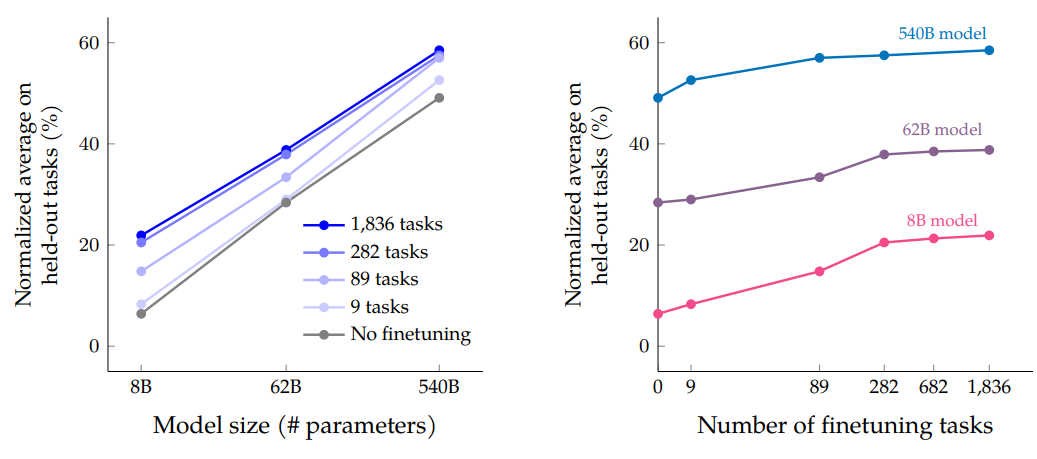
如下图所示是模型大小和微调任务数据量的规模测试
由图可知,增加微调任务数量可以提高性能,但超过282项任务提升较小
可能的解释有两种:1. 额外的任务不够多样化,没有为模型提供新的知识;2. instruction tuning大部分提升的来源是,模型在此过程中学习如何更好地表达预训练中已知的知识,超过282个任务没有太大帮助
另一方面,模型规模增加确实极大地提高了性能
值得注意的是,实验很难确定instruction tuning对对小模型还是对大模型的改进更大,因为尽管8B模型的绝对提升大于540B模型,但540B模型的错误率相对降低幅度更大
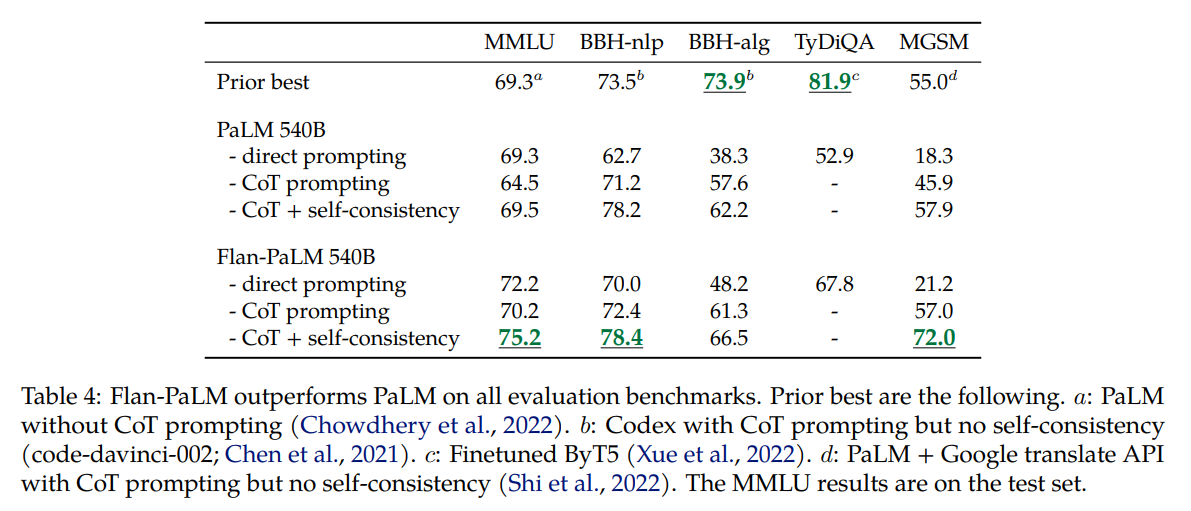
下图是对加入CoT数据集的测试,可见CoT与self-consistency对性能提升有明显帮助,但是在BBH(包含只需要符号操作的任务)上FLAN并没有达到SOTA
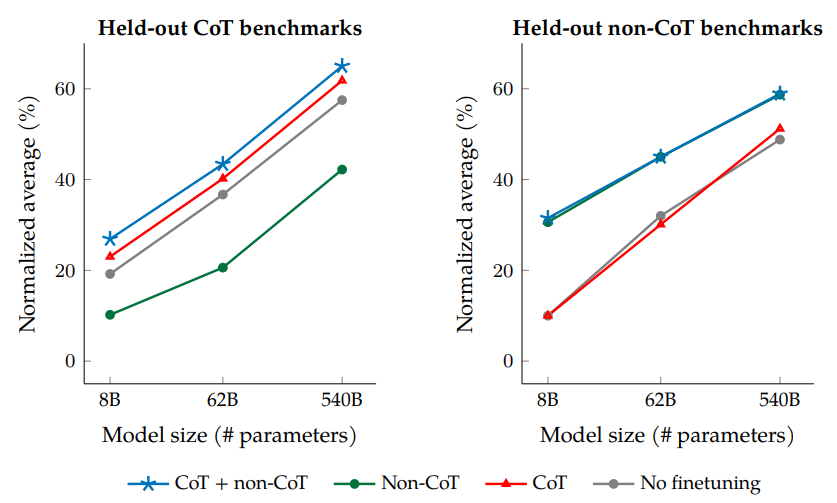
如图是CoT的消融实验,测试了只使用CoT/只使用non-CoT进行微调,在held-out CoT/non-CoT任务上的结果
注意到左图中只使用non-CoT进行微调时,在held-out CoT任务上测试时性能反而下降
另一方面,右图中若不使用non-CoT进行微调,在non-CoT上测试时性能没有提升
这个结果说明在微调中同时使用CoT和non-CoT非常重要
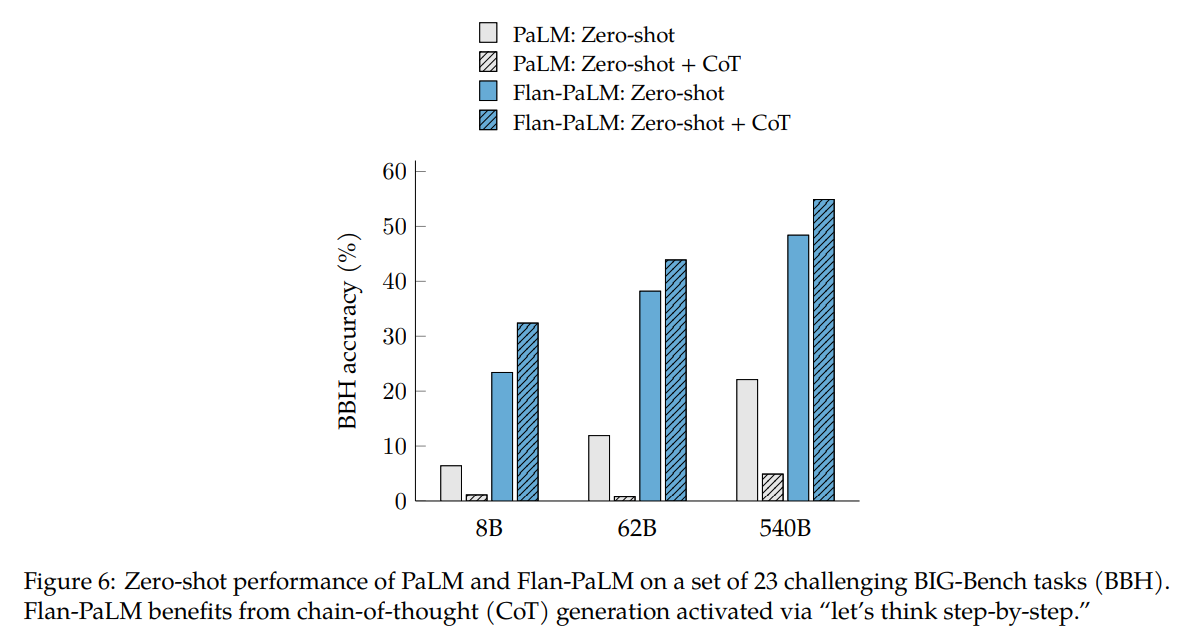
下图展示了CoT为模型带来的zero-shot能力,通过使用prompt “let’s think step-by-step”,FLAN模型的推理能力可以进一步提升
基于上述实验结果,论文训练了FLAN-PaLM和FLAN-T5,并进行了open-ended generation的人工评分测试,结果是大部分更偏爱FLAN版本
论文最后指出FLAN-T5/PaLM仍有一些缺点,例如继续生成相关文本而不是生成回答、重复输入问题的修改版本、不知道何时停止生成文本等等