
NExT-GPT Any-to-Any Multimodal LLM
Introduction
目前的多模态大模型 (MM-LLM) 研究大多关注输入端的多模态理解,而忽略了输出端的多模态生成
该论文提出了一种端到端的any-to-any多模态大模型NExT-GPT,旨在处理由文本、图像、视频、音频四种模态构成的任意输入输出
多模态大模型的常用方法是设计adapter将各模态的预训练编码器对齐到文本LLM
NExT-GPT采用的也是这种方法,如图所示,NExT GPT包括三层
首先,利用已有的encoder对各模态输入进行编码,并将单模态表示通过投影层投影到LLM可理解的类语言表示
然后,利用已有的开源LLM进行语义理解和推理,生成输出的text token,以及用于引导decoder生成多模态内容的”modality signal” token
最后,多模态信号和特定指示通过投影后,输入不同模态的decoder生成相应模态的内容
整个模型中只有投影层需要训练,各个encoder、decoder和LLM都是冻结的
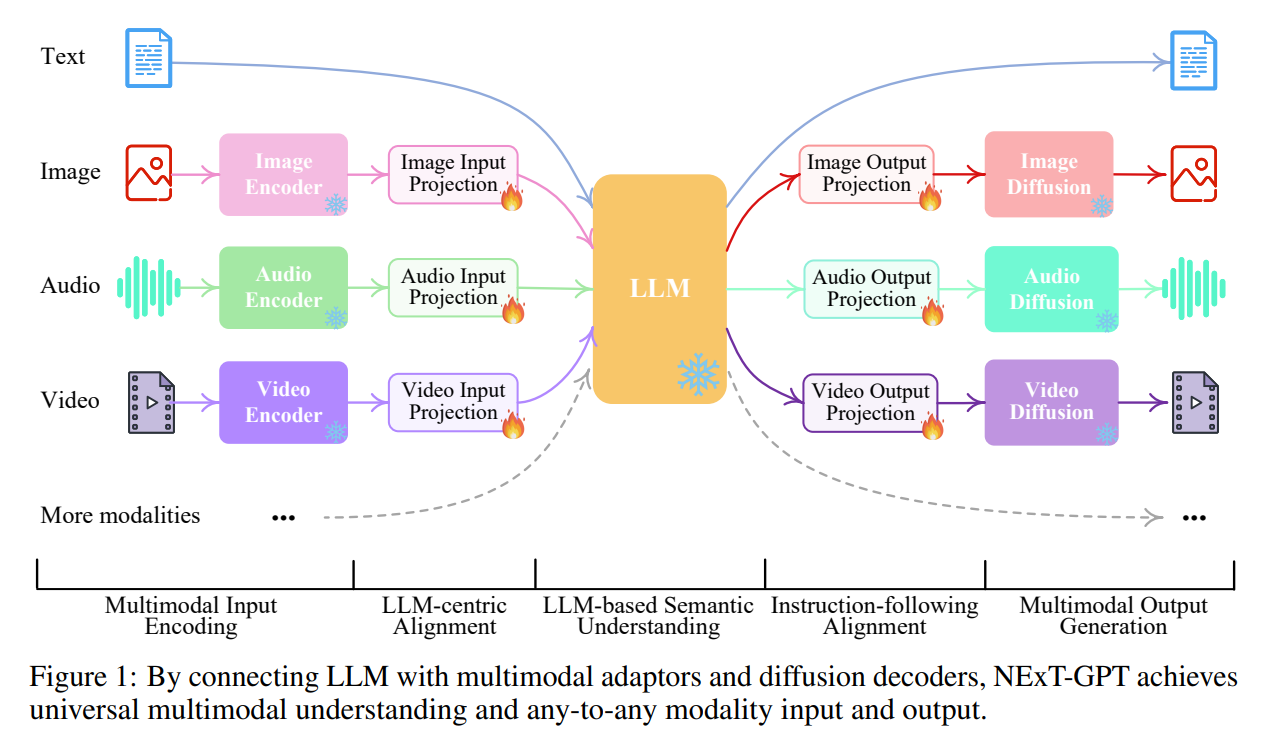
Architecture
Multimodal Encoding Stage:使用ImageBind,ImageBind是一个统一的跨6个模态的编码器,可以避免组织大量异质模态编码器的困难,encoder之后的映射层使用线性映射层
LLM Understanding and Reasoning Stage:LLM使用Vicunna,输出为文本响应以及各模态的signal token,信号用作decoder是否生成或生成什么多模态内容的指令
Multimodal Generation Stage:多模态信号首先通过transformer-based投影层,然后输入已有的隐条件扩撒模型:图像生成Stable Diffusion、视频生成Zeroscope、音频生成AudioLDM
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. CoRR, abs/2305.05665, 2023.
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 902023.
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the CVPR, pages 10674–10685, 2022.
Cerspense. Zeroscope: Diffusion-based text-to-video synthesis. 2023. URL https://huggingface. co/cerspense.
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo P. Mandic, Wenwu Wang, and Mark D. Plumbley. Audioldm: Text-to-audio generation with latent diffusion models. In Proceedings of the ICML, pages 21450–21474, 2023.
Alignment Learning
在encoder-side,投影层的目标是将多模态特征与文本特征对齐
论文通过X-caption任务学习encoder-side对齐,即令LLM产生各个输入模态的caption,其中X表示image、audio或video
在decoder-side,由于各个模态的扩散模型都仅以文本输入作为条件,导致条件扩散模型不能直接解释LLM输出的模态信号,因此decoder-side投影层的目标是使得LLM输出的模态信号与条件扩散模型对齐
如果对齐过程涉及到整个扩散模型的前/后向传播,显然计算量将会很大
论文提出的训练称为instruction-following alignment,其目标是尽可能令投影层输出的modal signal token representation和扩散模型编码的conditional text representation之间的距离尽可能小
该训练任务只涉及caption文本,不涉及图片、视频等,保证了训练轻量化
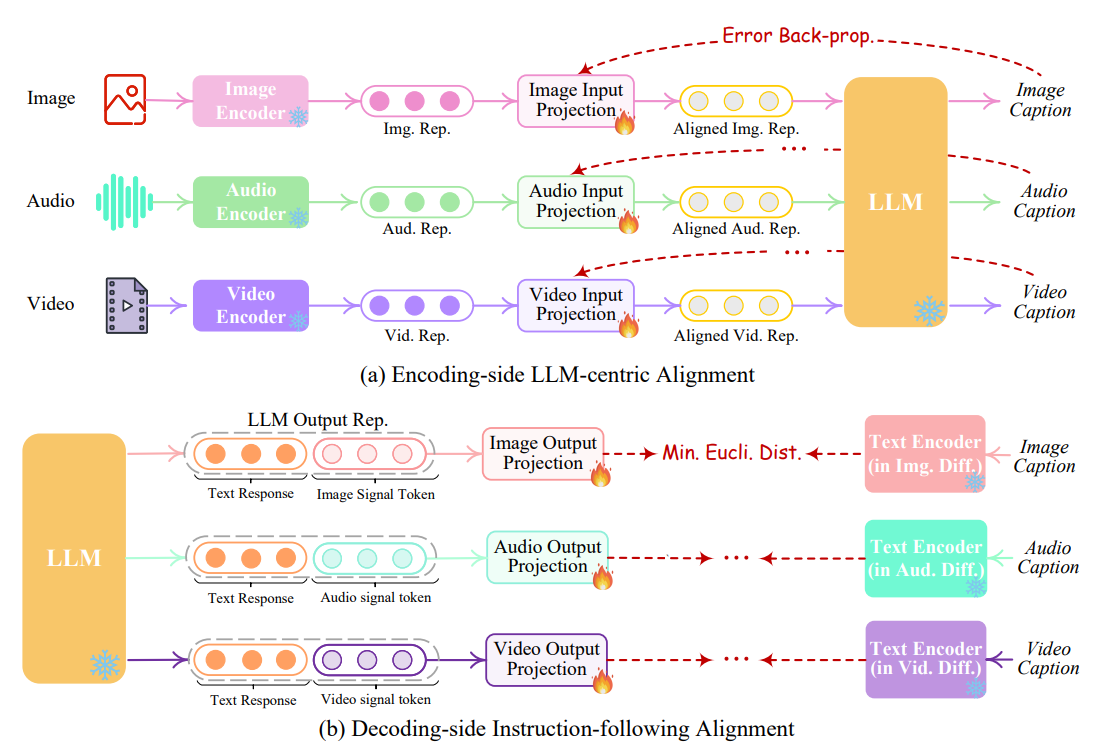
Instruction Tuning
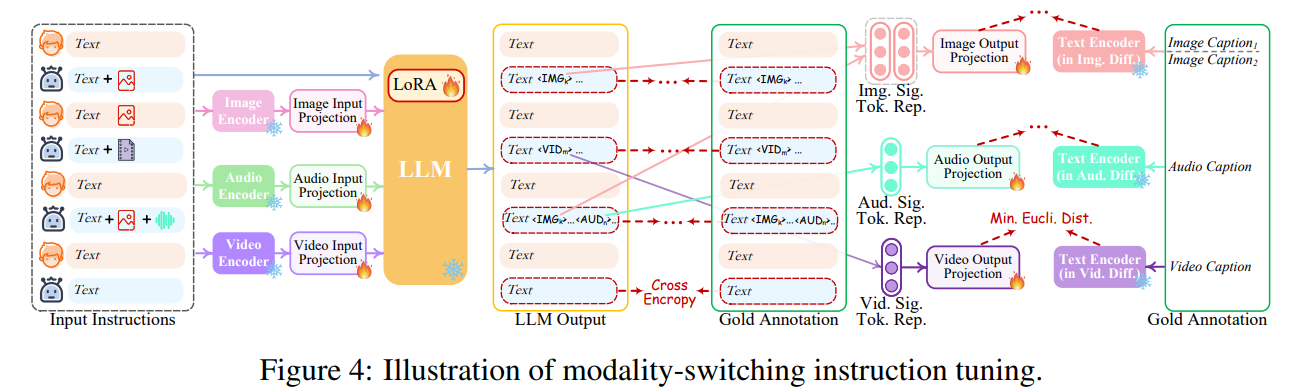
虽然encoder-side和decoder-side都各自进行了对齐,但整体模型还是缺少根据多模态信息理解用户指令的能力,因此论文进一步使用instruction tuning (IT)解决这个问题
如图所示,论文利用LoRA使LLM中的一小部分参数能够在IT阶段与投影层同时更新
多模态对话样本被输入系统后,LLM需要重建输入的文本内容,并用multimodal signal token表示多模态内容
此外论文还微调了NExT-GPT的decoder-side,即将投影层输出的modal signal token representation和扩散模型编码的conditional text representation对齐
为了完成这样的多模态IT,论文构建了新的MosIT数据集
Experiment
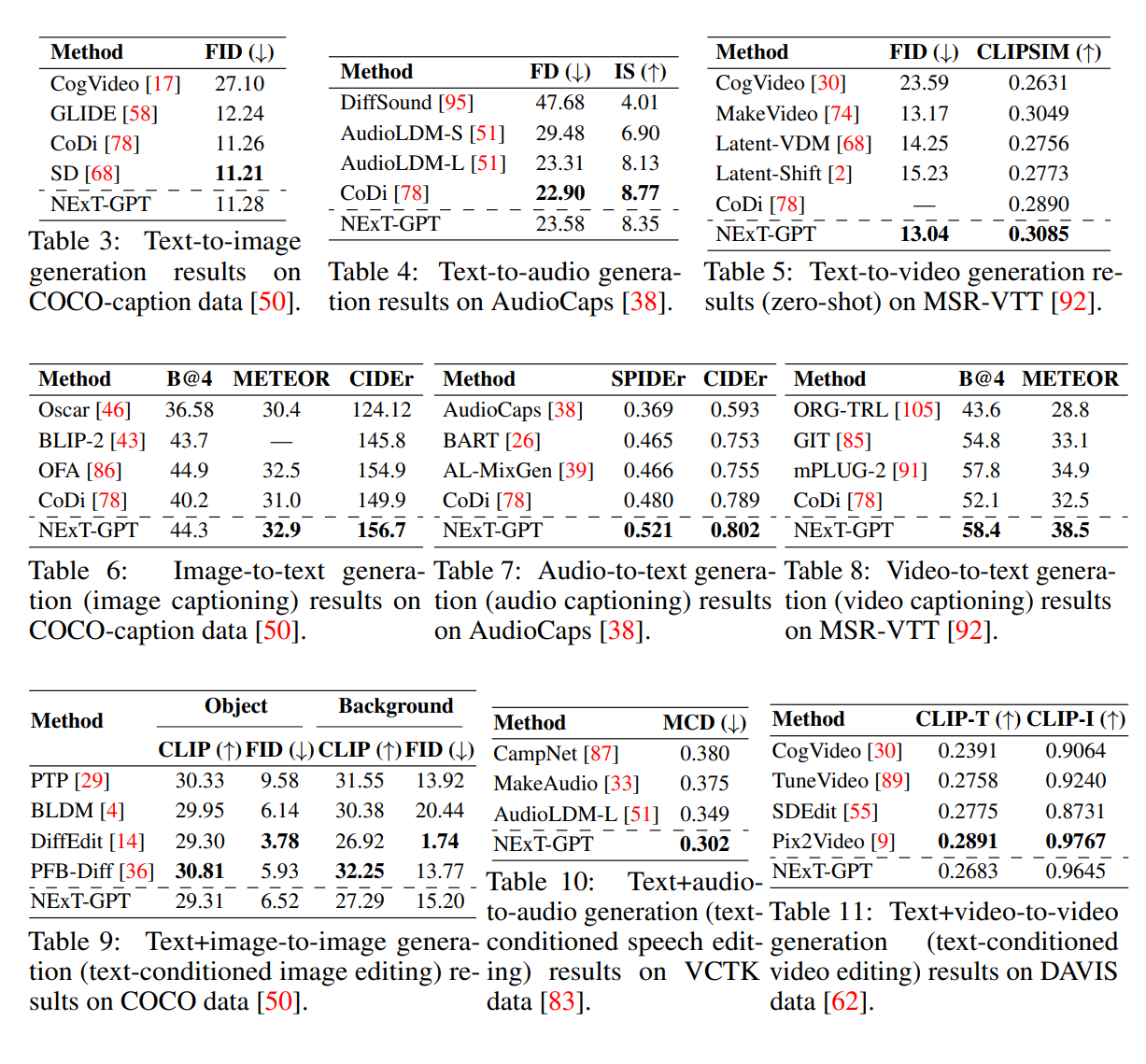
如图所示是NExT-GPT的any-to-any生成的量化结果,虽然不是全部达到SOTA,但都展现出了很好的性能
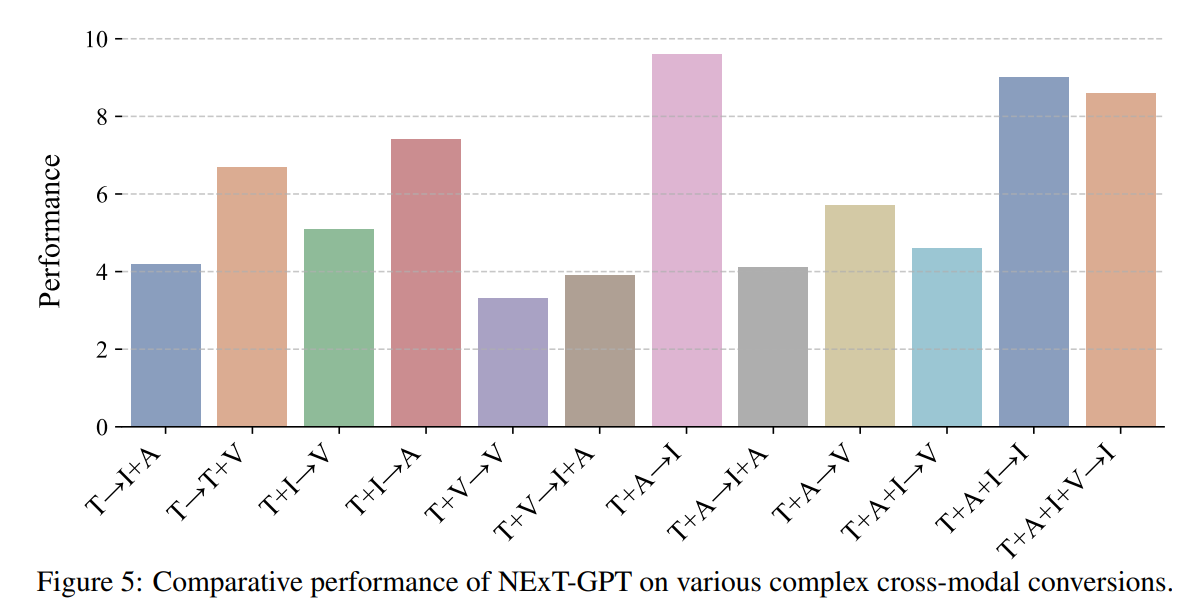
下图是复杂any-to-any QA的人类评估,分值范围1~10
还有一些生成结果的图可以直接看论文和官网