InstructGPT论文解读
Introduction
众所周知,大语言模型(LLM)可以通过prompt执行一系列NLP任务
然而LLM仍经常产生捏造事实、生成biased/toxic text、不遵循用纸指令的行为
这种现象的原因是LLM的训练目标——预测网络文本的下一个token,与“安全有效地遵循用户指令”的目标不同,因此论文称语言建模的目标是未对齐的(misaligned)
为了使LLM实现helpful、honest and harmless的目标,论文对使用RLHF (reinforcement learning from human feedback)微调LLM的方法进行了研究,即使用人类偏好作为奖励信号微调模型
作者们雇佣了一个40人团队进行数据标注(称他们为labeler),构建了两个数据集
第一个数据集,首先收集用户提交给语言模型API的prompt和一些labeler写的prompt,然后让labelers标注期望的人工回复,这个数据集用于有监督微调(supervised fine-tuning, SFT)得到baseline model
第二个数据集,给API输入更多的prompt,让labelers对输出进行比较打分,这个数据集用于训练奖励模型(reward model, RM),之后RM用于辅助PPO算法对baseline model进行进一步微调
论文使用该方法对GPT-3进行了微调,得到的模型称为InstructGPT
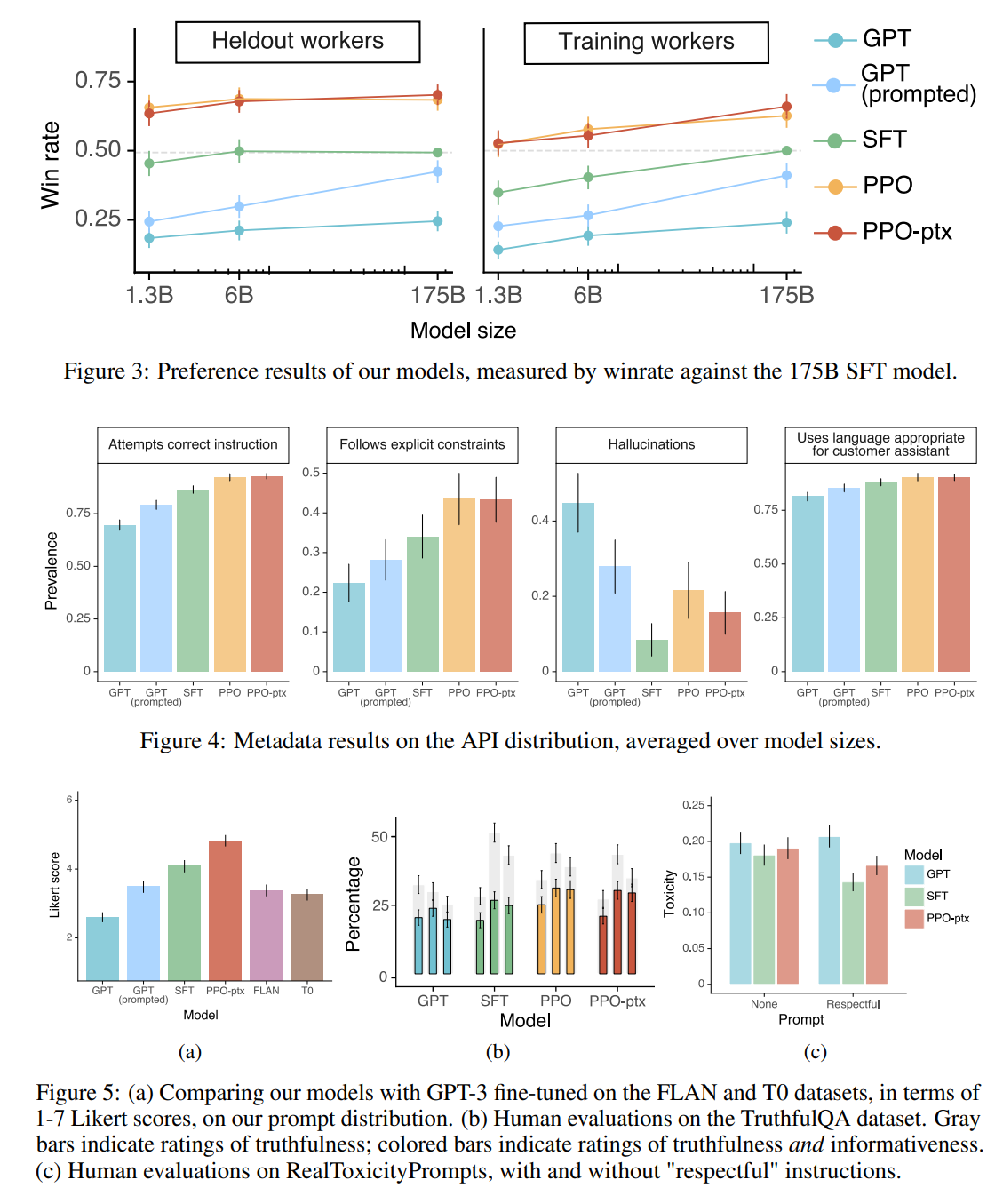
实验的主要结果总结如下
- 相比于GPT-3(175B),InstructGPT(1.3B)的输出明显更受labelers偏爱
- InstructGPT在真实性(TruthfulQA benchmark)上有明显提升
- InstructGPT在toxicity上略有改善,但在bias上没有
- 通过修改RLHF的微调过程,InstructGPT可以最小化公开NLP数据集上的性能回归(performance regressions)
- 泛化性上,”held-out” labelers(没有通过筛选的labelers,他们没有参与训练数据标注)相较GPT-3更偏爱InstructGPT的输出
- 公开NLP数据集不能反映InstructGPT的性能
- InstructGPT对RLHF微调分布之外的指令也具有很好的泛化能力
- InstructGPT仍然会犯简单错误
Method
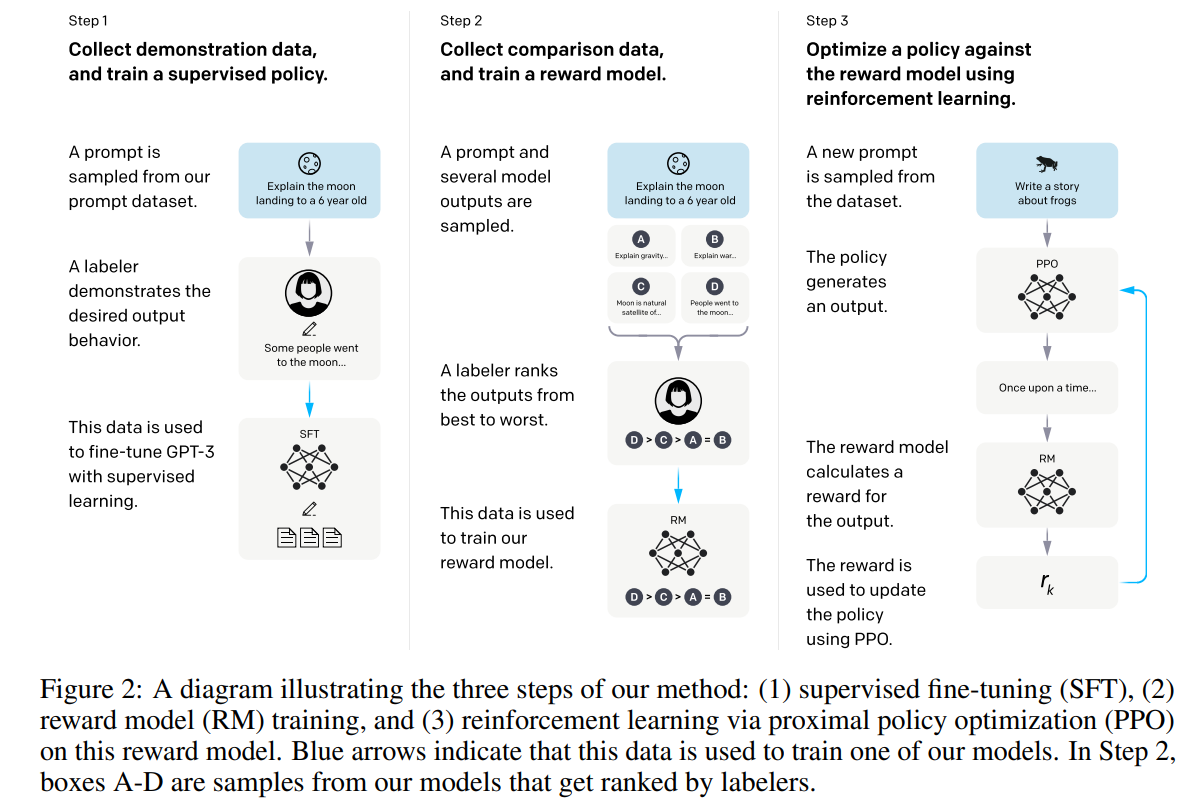
如图所示,InstructGPT的微调分为三步
- 收集注释数据,训练有监督微调模型(SFT model)
- 收集对比数据,训练奖励模型(RM)
- 通过RM使用PPO优化策略
Dataset
首先是数据集中prompt的收集
prompt主要收集自商业语言模型API的提交文本,还有少量来自labelers编写,其中96%是英语,数据集保证prompt多样化,且进一步应用了启发式降重,此外还过滤了包含个人身份信息的prompt
根据手机的prompt,论文生成了三个不同的数据集
- SFT数据集,用于训练SFT模型,包含labelers针对prompt编写的人工响应,约13k个prompt样本
- RM数据集,用于训练RM,包含labelers根据偏好对模型输出进行的比较打分,约33k个prompt样本
- PPO数据集,没有人工标签,用作RLHF微调的输入,约31k个prompt样本
接下来是人类标注数据收集
labelers需要对不同人口群体的偏好敏感,且善于识别潜在有害输出,因此雇佣的团队进行了筛选测试
为了测试泛化性能,作者们还雇佣了一组”held-out” labelers,他们不参加筛选测试,也不参与标注数据
虽然prompt很多样且复杂,但labeler的意见一致性非常高,他们有72.6±1.5%的一致率,对于”held-out” labelers则有77.3±1.3%
Model
SFT:微调GPT-3,具体训练参数可见论文
RM:一个 6B的模型,输出是标量分数
对于同一个输入prompt,labelers对$K$个模型输出按好坏进行排序,于是RM的loss为
其中$x$是prompt,$yw,y_l$是语言模型对$x$的输出,$y_w$是排序更高的输出,$r{\theta}(x,y)$是RM输出的标量分数,系数$\frac{1}{\binom{K}{2}}$是因为排序涉及$C_{K}^2$次比较,$K$取4~9
RL:使用PPO算法,每个epsiode仅含一对prompt-response和其reward
此外为防止RL过度优化,论文还使用了per-token KL惩罚,这个模型被称为PPO
为了防止公开NLP数据集上的性能回归,论文进一步融合了预训练梯度,此时的模型成为PPO-ptx
其中$D{\pi{\phi}^{\mathrm{RL}}}$是RL策略,$\pi^{\mathrm{SFT}}$是已训练的SFT策略,$D_{\mathrm{pretrain}}$是与训练分布
Experiments
论文结果部分主要是对introduction中总结的结果进行详细说明,具体可以直接看论文