
ALBEF论文解读
Introduction
大多数已有的VLP方法(UNITER、OSCAR等)依赖于预训练目标检测器来提取图像区域特征,再设计多模态编码器将图像特征与文本嵌入融合,其预训练任务一般是masked language modeling (MLM)
这样的框架存在几个局限
- 图像特征与文本嵌入的语义空间不同,使得多模态编码器难以对其交互进行建模
- 目标检测器的计算消耗大(需要大分辨率图像)、数据注释消耗大(需要大量边界注释)
- 广泛使用的从网络收集的image-text数据集固有地存在噪声,现有的预训练目标(如MLM)可能过拟合噪声并降低泛化性能
因此该论文提出了新的VLP框架ALign BEfore Fuse (ALBEF),其特点是
- 使用无目标检测器的图像编码器
- 引入image-text contrastive (ITC)损失
- 提出Momentum Distillation (MoD)解决噪声问题
Pre-training Method
模型结构如图所示,其中包含image encoder、text encoder和multimodal encoder三个模块
image encoder由image encoder,text encoder和multimodal encoder分别由预训练BERT前6层/后6层初始化
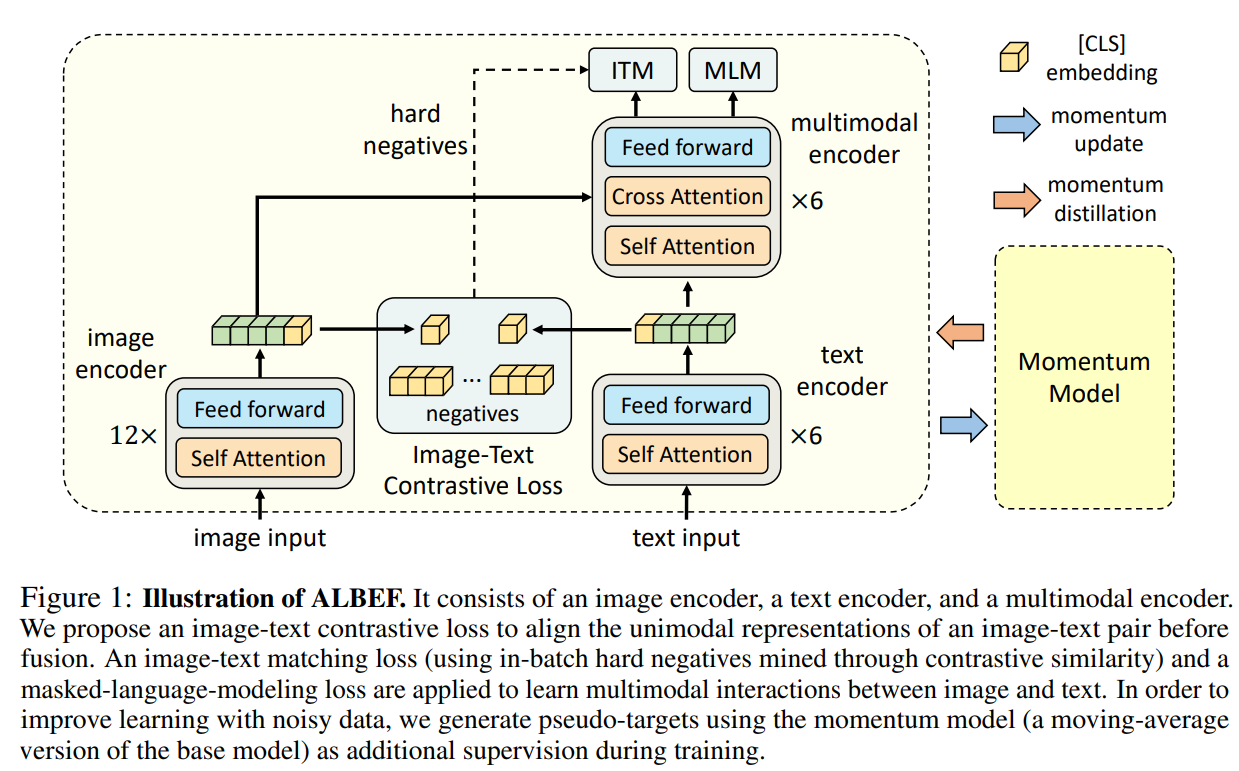
ALBEF的预训练目标有三个
Image-Text Contrastive Learning (ITC)
对比学习要求positive pair拥有更高的相似度,negative pair则反之
其中用于对比的image/text representation是image/text encoder的[CLS]输出嵌入
对于positive pair $(I,T)$,ITC目标是最大化image-to-text和text-to-image相似度,即最小化如下损失(目标为one-hot标签的交叉熵损失)
其中$s$是相似度函数,$\tau$是温度参数
这个损失可以视为对称版的InfoNCE
ITC将两个单独的模态视为image-text pair的两个视角,并训练单模态编码器最大化两个视角之间的互信息
更具体的,ITC在实现上还使用了Momentum Contrast (MoCo)技术
引入ITC的好处有
- 将图像特征和文本特征对齐,使得多模态编码器更容易进行跨模态学习
- 使得单模态编码器更好地理解图像和文本的语义
- 通过contrastive hard negative mining,可以为后续的image-text matching挖掘到信息量更大的样本
Masked Language Modeling (MLM)
经典的MLM任务,由multimodal encoder对mask token进行预测
Image-Text Matching (ITM)
即判断image-text pair是否匹配的二分类,使用multimodal encoder的[CLS]输出嵌入进行投影预测
论文在ITM训练中提出了一种方法采样hard negative pair
其中negative hard image-text pair的定义是,它们语义相近,但是在细粒度细节上存在差异
对于batch中的每个图像,论文按照对比相似度分布(由ITC获得)从batch中采样一个negative text,其中与图像更相似的文本采样几率更高,类似的,对每个文本也采样一个hard negative image
Momentum Distillation (MoD)
用于预训练的image-text pair大多是从网络上收集的,其常常存在噪声
其中的positive pair通常是弱相关的:文本可能包含与图像无关的单词,或者图像可能包含文本中没有的实体
对于ITC,图像的negative text也可能与图像相匹配;对于MLM,可能存在与注释不同的词语能同样好地描述了图像,然而ITC和MLM的one-hot会惩罚所有错误预测
为解决该问题,论文提出使用动量模型 (momentum model) 生成的伪目标进行学习
momentum model是unimodal/multimodal encoder的exponential-moving-average版本
MoD训练base model使其与momentum model的预测相匹配
对于ITC任务,其损失为
其中$p$和$q$分别表示base model和momentum model输出的softmax归一化相似度
该损失能最大化与同一图像具有相似语义的不同文本的互信息,因为这些文本具有更大的$q$,同理对具有相似语义的图片也是,因此可以认为MoD起到了数据增强的作用
对于MLM任务则有
其中$p$和$q$分别表示base model和momentum model输出的mask token概率分布