
BLIP-2论文解读
该论文的motivation是利用冻结的预训练视觉模型和大语言模型进行VLP研究,以提高VLP大模型的效率
由于视觉模型和大语言模型各自只进行了单模态预训练,而冻结它们又使其无法直接互动学习多模态对齐
因此论文提出了一个Q-Former结构充当连接两者的桥梁
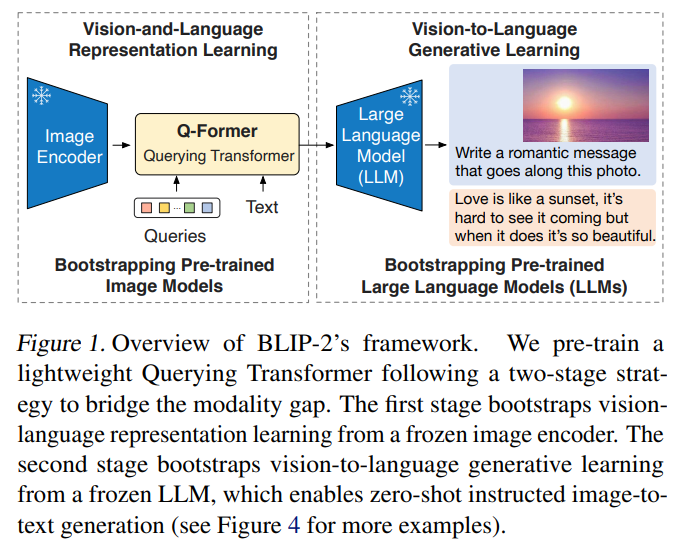
Method
如图所示,Q-Former包含image transformer和text transformer两个子模块,两者参数共享,初始化为预训练BERT base
image transformer的输入是一组可学习的query embedding,输出是提取的视觉特征,实验中使用32个768维queries,相应输出记为$Z\in R^{32\times 768}$
text transformer可以同时用作text encoder或text decoder
Q-Former与训练包含两个阶段,第一个阶段的目的是训练Q-Former的表示能力,该阶段Q-Former只连接预训练视觉模型
类似于BLIP,训练目标有三个
Image-Text Contrastive Learning (ITC) :即正负image-text pair对的对比学习
[CLS] token的text transformer输出$t$视为文本表示,$Z$为视觉表示,由于$Z$包含多个输出embedding,论文的做法是选择与$t$相似度分数最高的一个嵌入作为结果
此外,SA层中query和text不允许互相注意
ITC用于学习image representation和text representation的对齐
Image-grounded Text Generation (ITG):也即BLIP中的LM,根据给定图像生成文本
该任务SA层中query之间可以相互注意,但不能注意text部分,同时text只能注意query和之前的text
ITG将强制query提取对文本生成有用的视觉信息
Image-Text Matching (ITM):即image-text pair是否匹配的二分类
该任务SA层中所有query和text可以相互注意
ITM用于使$Z$捕捉到多模态信息
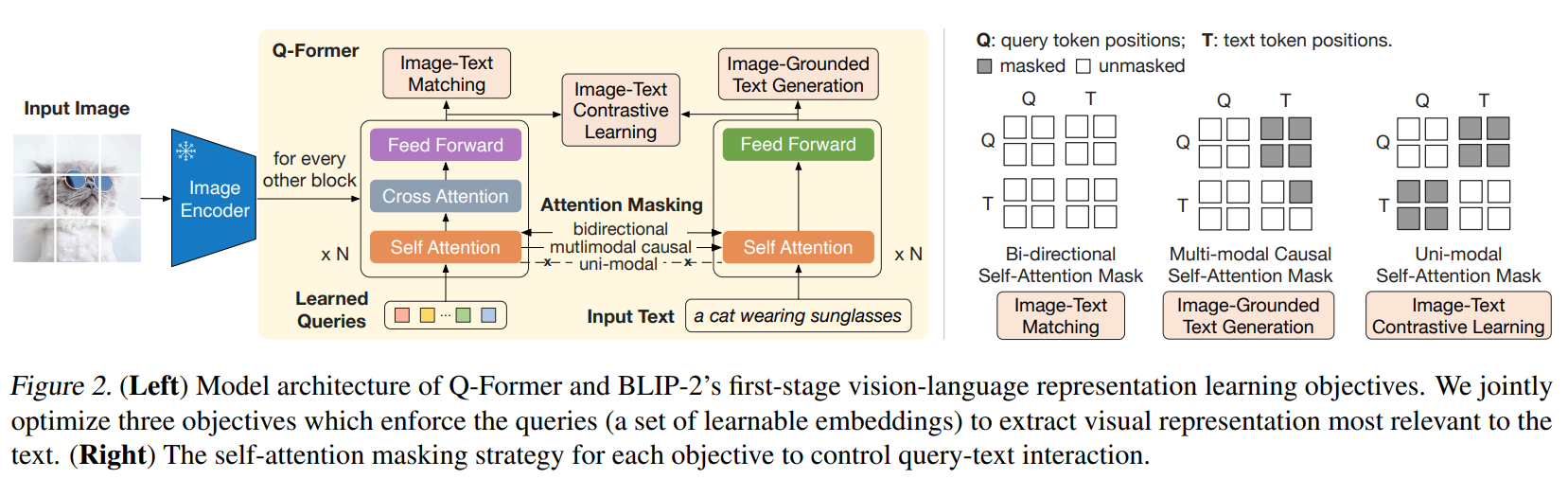
第二个阶段目的是使Q-Former学得生成能力
该阶段在输出query embedding $Z$之后连接一个FC层(使嵌入维度与文本嵌入相同),并将映射后的嵌入添加为LLM输入文本的前缀,这些嵌入的功能是LLM的soft visual prompts
LLM可以是decoder-based或者是encoder-decoder,预训练任务是language modeling
具体来说,对于decoder-based LLM,预训练任务是基于映射的query embedding生成文本
对于encoder-decoder LLM,预训练任务是将映射的query embedding和一部分文本前缀输入encoder,要求decoder生成后续文本
论文实验主要进行了Image Captioning、VQA和Image-Text Retrieval的微调实验以及VQA的zero-shot实验,具体见论文