BLIP论文解读
Introduction
已有的VLP模型存在两方面的局限
Model perspective:encoder-based模型(CLIP、ALBEF等)难以直接迁移到文本生成任务,encoder-decoder模型(VL-T5、SimVLM等)难以适应image-text retrieval任务
Data perspective:已有的SOTA模型都使用收集自网络的大规模数据集训练,其中包含大量噪声
BLIP论文从以上两个角度提出了解决方案
模型角度,提出Multimodal mixture of Encoder-Decoder (MED) 结构,统一unimodal encoder、 image-grounded text encoder和image-grounded text decoder
数据角度,提出数据集增强方法Captioning and Filtering (CapFilt),将预训练MED微调成两个模块,captioner用于生成给定网络图像的合成字幕,filter用于从原始网络文本与合成文本中去除噪声
MED
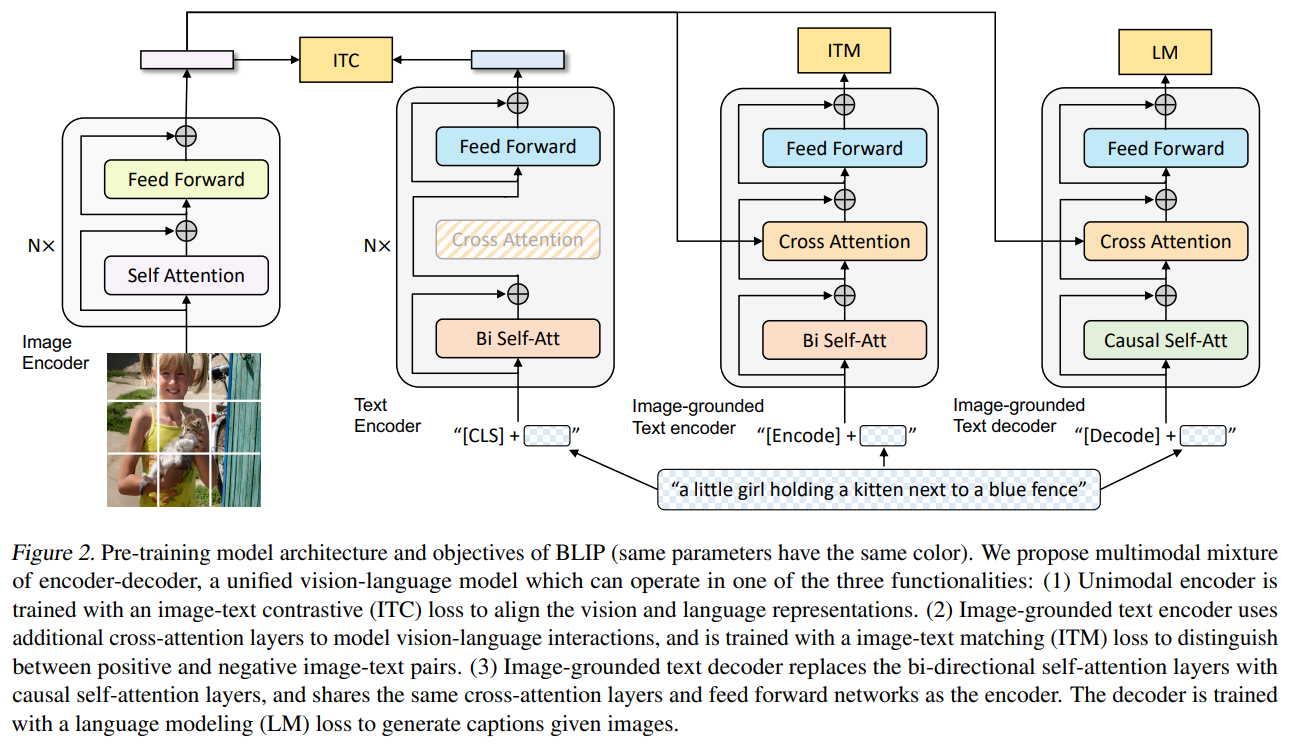
MED中Image Encoder使用预训练ViT,Text Encoder使用预训练BERT
MED的目标是用统一结构提供三种功能
unimodal encoder:使用Image Encoder和Text Encoder分别独立得到单模态编码
image-grounded text encoder:旨在得到多模态表示,通过在self-attention层和FFN层中间添加额外的cross-attention层,使Image Encoder编码的视觉信息插入Text Encoder,Text Encoder输入文本开头添加[Encode] token,其对应输出作为多模态表示
image-grounded text decoder:旨在进行文本生成,结构与image-grounded text encoder类似,只是双向self-attention变为单向,[Decode] token用于标记输入开始,end token标记输出结束
为了达到上述目标,MED的训练使用了相应的三种任务
Image-Text Contrastive Loss (ITC):用于训练unimodal encoder,任务是使positive pair有相似表示,negative pair则相反,BLIP采用了与ALBEF相同的对比损失
Image-Text Matching Loss (ITM):用于训练image-grounded text encoder,任务是判断image-text pair是否匹配的二分类,使用了ALBEF中的hard negative mining
Language Modeling Loss (LM):用于训练image-grounded text decoder,任务是对于给定图像生成描述文本
与训练中除了SA层,其余参数均共享,因为encoding和decoding需要分别由双/单向SA实现
CapFilt
此前许多研究使用自动爬取的image alt-text pair数据集进行训练,虽然规模变大,但噪声非常多
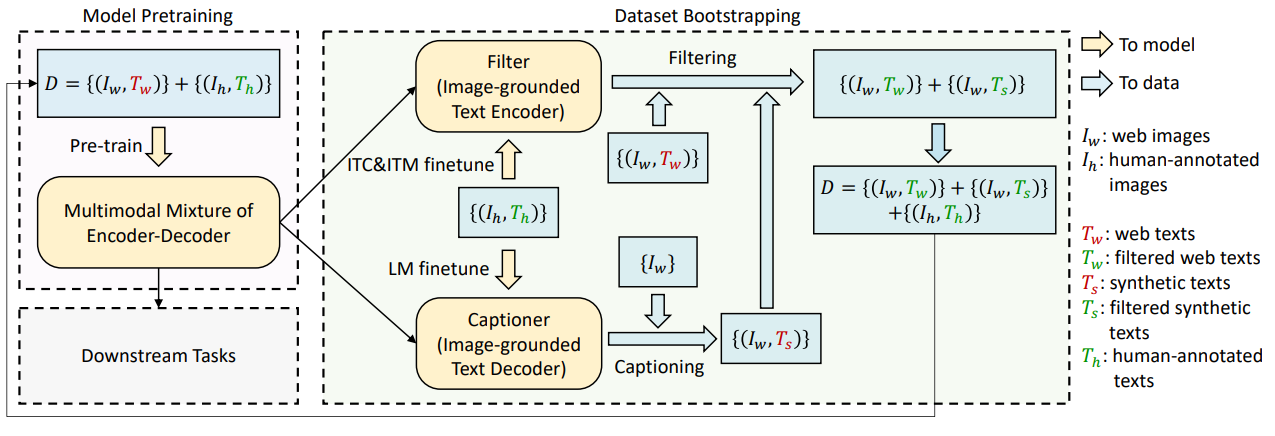
我们将高质量的人类标注image-text pair数据集(例如COCO)记为${(I_h,T_h)}$,网络爬取的大规模噪声数据集记为${(I_w,T_w)}$
CapFilt首先使用预训练MED初始化captioner和filter两个模块,其中captioner用于生成给定网络图像的字幕,filter用于去除噪声图像-文本对
之后在COCO数据集上单独进行微调,具体来说,captioner是一个image-grounded text decoder,通过LM loss微调,filter是一个 image-grounded text encoder,通过ITC和ITM微调
微调后,给定网络图像$I_w$,captioner将生成合成字幕$T_s$,之后filter同时移除$T_w$和$T_s$中的噪声文本,过滤后的新数据可以与原高质量数据组合成更大的数据集
Experiment
CapFilt和SA参数共享的消融实验不说了,具体可以看论文,这里主要关注一下下游任务的应用
Image-Text Retrieval:使用ITC和ITM loss在COCO数据集上微调,推理时先通过图像/文本特征相似度选择k个候选,再通过ITM score进行排序
Image Captioning:使用LM loss在COCO数据集上微调,推理时添加prompt “a picture of”
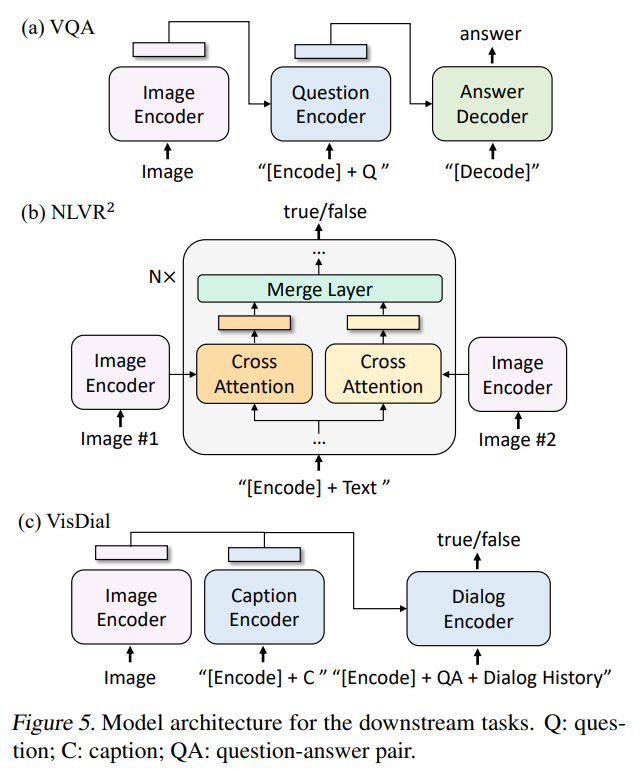
Visual Question Answering (VQA):BLIP将其视为生成任务,如图所示,先将image-question编码为多模态嵌入,再通过decoder生成回答
Natural Language Visual Reasoning (NLVR^2 ):该任务需要模型预测一个句子是否是一对图片的描述,BLIP对预训练image-grounded text encoder结构做了一个简单修改,如图所示,预训练CA层在微调时被复制为两份,分别用于处理两张图片,之后在FFN层之前融合(平均池化和拼接)两个CA层的结果
Visual Dialog:BLIP将其视为候选排序任务,先将image-caption编码为多模态嵌入,再结合dialogue history等输入encoder,通过ITM loss训练
这些下游任务的数值结果具体可以看论文
论文还有一个有意思的实验是Video-Language任务的Zero-shot迁移
论文从视频中均匀采样n帧并拼接为图像序列作为输入,即使存在领域差异且缺少时序建模,但BLIP仍达到了SOTA