A Simple Review of Pre-training Models for Dialogue System
Large-scale transfer learning for natural language generation
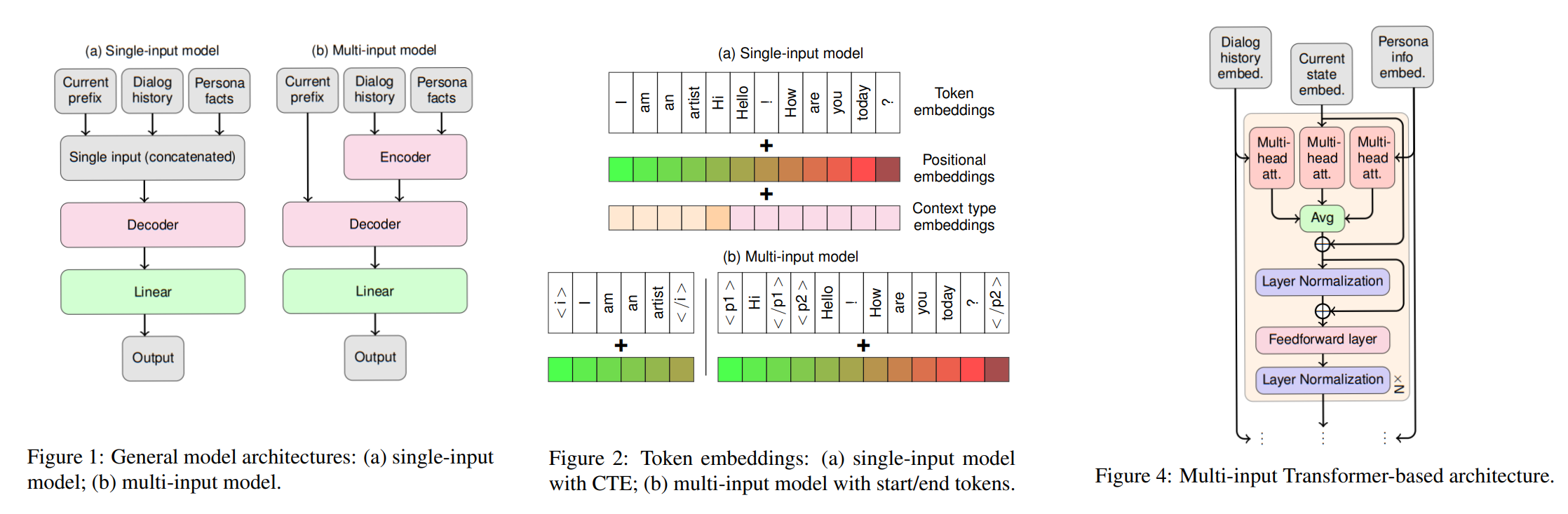
这是一篇将预训练模型应用到NLG任务的较早研究,主要探索了如何使单输入预训练模型适用于下游多输入生成任务
以对话系统为例,其输入包括:知识库中的知识、对话历史和已生成的输出token序列
文章提出了两种基本方案
- single-input model
不改变预训练模型结构,仅将输入进行拼接作为前缀,预训练模型的目标使对其进行续写
为了区分该前缀中的异构上下文(heterogeneous contexts),文章列出了几种方法:
(1) 使用自然分隔符(例如双引号)对不同context的输入进行分隔
(2) 使用空间分隔符进行分隔
(3) 将context-type embeddings与原始token embedding进行融合
- multi-input model
对预训练模型进行复制形成encoder-decoder结构
与single-input model类似,encoder的输入是加入了类型embedding的拼接上下文,而已生成的输出token序列则作为decoder的输入
此外,decoder中的multi-head attention被复制成三份,分别处理知识嵌入、对话历史嵌入和已生成输出的嵌入
实验中,在BLEU、NIST-4等标准下multi-input model均表现更优秀
此外,single-input model更倾向于生成历史中已有的单词,且multi-input model在利用知识上也更加优秀
Dialogpt: Large-scale generative pre-training for conversational response generation
这篇文章是将GPT-2直接应用于open domain dialogue system的早期尝试
DialogueGPT直接基于GPT-2进行fine-tuning,其输入就是对话历史和目标响应的拼接
为了使生成的响应更丰富,DialogueGPT还加入了了最大互信息(maximum mutual information, MMI)分数
MMI使用一个预训练反向模型,通过给定的输出响应预测其输入,即预测$P(source|target)$
具体的,DialogueGPT选择k个概率最大的输出,并根据反向模型预测的概率重新排列其顺序
此外,文章还尝试了强化学习方法,即使用$P(source|target)$作为reward进行policy gradient,但实验表明该方法会陷入局部最优
总的来说这篇文章没有用什么比较新的方法,只是对预训练模型在dialogue system上的应用做了实验探索
Knowledge-grounded dialogue generation with pre-trained language models
这篇文章提出了一种将基于预训练模型和基于知识的对话生成相结合的模型
对于外部知识我们主要考虑非结构化文档,例如wiki等
预训练语言模型通常会限制最大的可处理token数,因此直接将非结构化文档作为输入并不现实
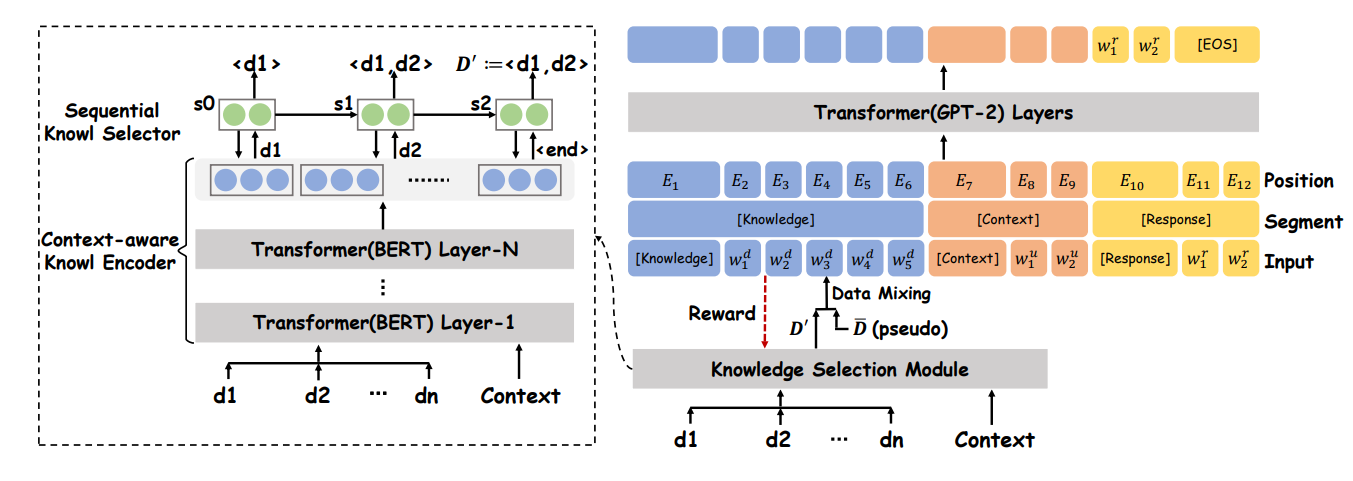
文章提出的做法是在预训练模型前添加一个知识选择模块
假设知识文档为$D={d_1,\cdots,d_m}$,知识选择模块将知识选择视为序列预测任务,即从空集开始,使用LSTM每个timestep预测一个相关知识$d_i$加入集合,直到生成一个特定的终止符
为了充分理解对话历史和知识之间的关系,令完整的对话历史${uk}{i=k}^n$与各个不同的知识$d_i$进行拼接,记为$s_i$,每个$s_i$经过预训练BERT处理得到$e_i=CLS(BERT(s_i))$,即构成了LSTM的输入$E=(e_1,\cdots,e_m)$
知识选择后,使用预训练模型进行对话生成的方法就是简单的拼接以及embedding融合
现在要考虑的是在目标指示未知的情况下如何训练知识选择模块
由于目标响应$r$是由相关知识产生的,因此我们可以利用其生成伪ground truth
具体来说,将知识选择模块选择的知识按$Sim(di,r)$排序,然后取其子集$\bar D={d{j1},\ldots,d{j\bar m}},\bar m=\operatorname{argmax}t(\operatorname{Sim}(d{j_{1:t}},r))$作为伪ground truth,并利用其进行强化学习和课程学习
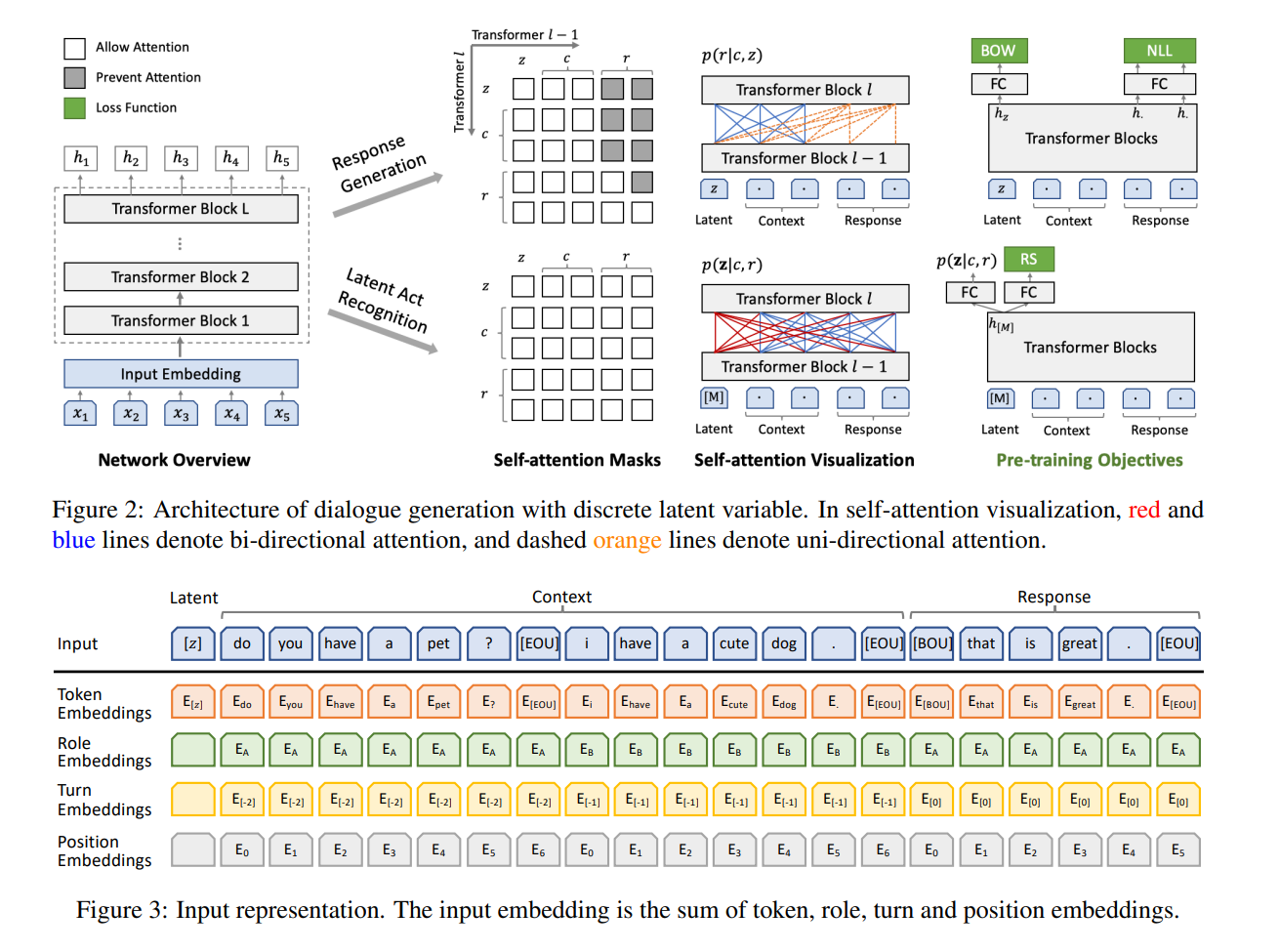
Plato: Pre-trained dialogue generation model with discrete latent variable
这篇文章的motivation是解决BERT在小型对话数据集上微调时表现不足的问题
文章认为造成上述问题的原因是:(1) 对话的语言模式与与训练使用的通用文本存在很大差距; (2) 单向文本生成与BERT的双向预训练模式不同; (2) 对话生成存在一对多关系,即同一context可对应多个合适的回复
针对(1),文章进一步使用了Reddit和Twitter收集的对话进行预训练
针对(2),文章使用了Unified language model pre-training for natural language understanding and generation. arXiv preprint中提出的结构
针对(3),文章使用了一个k路离散隐变量建模一对多关系
PLATO使用同一个预训练BERT同时进行隐变量$z$的预测和响应$r$的生成
响应生成使用$(z,c,r)$的拼接作为输入,其中$c$为上下文(对话历史、知识等),$z,c$的部分使用双向attention,$r$的部分只使用前向attention,损失函数同时使用NLL loss和BOW loss
隐变量预测使用$([M],c,r)$的拼接作为输入,其中$[M]$为特殊token,attention均为双向,输出为$z=CLS(BERT([M]))$
由于$z$是无监督的,因此loss通过分类实现,即选择正负对$(c,r^+),(c,r^-)$,通过$CLS(BERT([M]))$进行二分类,于是有二值交叉熵$L_{RS}=-\log p(l_r=1|c,r^+)-\log p(l_r=0|c,r^-)$
一次迭代的损失就是$L=L{NLL}+L{BOW}+L_{RS}$
此外BERT的输入使用了三种额外的embedding:(1) Role Embedding,输出响应对应的说话人为$E_A$,其余均为$E_B$;(2) Turn Embedding,用于区分utterance顺序,输出相应对应$E_0$,向前以此为-1,-2,…;(3) Position Embedding,不用解释
推理阶段,先产生k路离散隐变量$z$,使用其产生$k$个回复$r$,并选择概率$p(l_r=1|c,r)$最大的一个
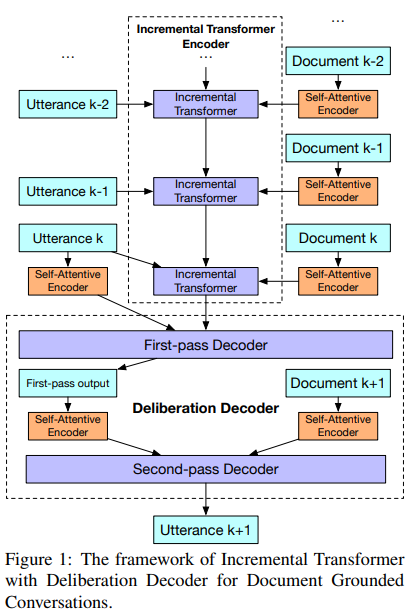
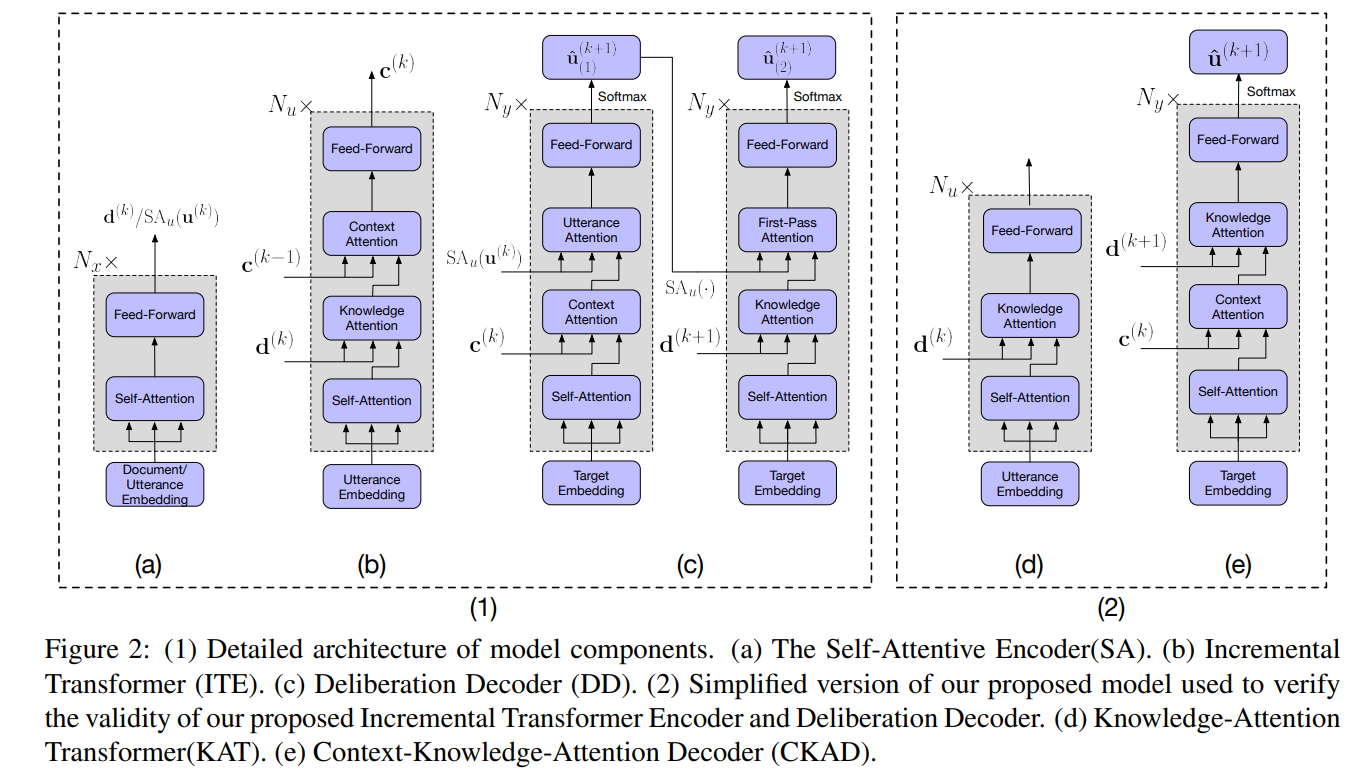
Incremental transformer with deliberation decoder for document grounded conversations
这篇不是预训练的dialogue system,但是是基于文档知识的dialogue system比较典型的transformer结构
模型结构看图就能大概理解,想深入阅读就直接看论文吧