A Review of Recent Multimodal ERC model
这篇文章简述了21~23年的一些有代表性的Multimodal ERC (Multimodal Emotion Recognition in Conversation) 模型,它们的共同点是都基于GNN (Graph Neural Network)
为方便描述,这里先做一个统一的符号定义
一段对话由$N$个utterance ${u_1,\cdots,u_N}$组成,每个$u_i$包含听觉、视觉、文本三个模态,记为$u_i={u_i^a,u_i^v,u_i^t}$,其中$u_i^a\in R^{d_a},u_i^v\in R^{d_v},u_i^t\in R^{d_t}$分别为已提取的听觉、视觉、文本特征,每个$u_i$对应一个情感标签$y_i$
每段对话包含$M$个speaker ${p1,\cdots,p_M}$,$p{\phi(ui)}$表示$u_i$对应的speaker,$U{\lambda}$(或$U^{(\lambda)}$)表示来自$p_{\lambda}$的utterance集合
MMGCN
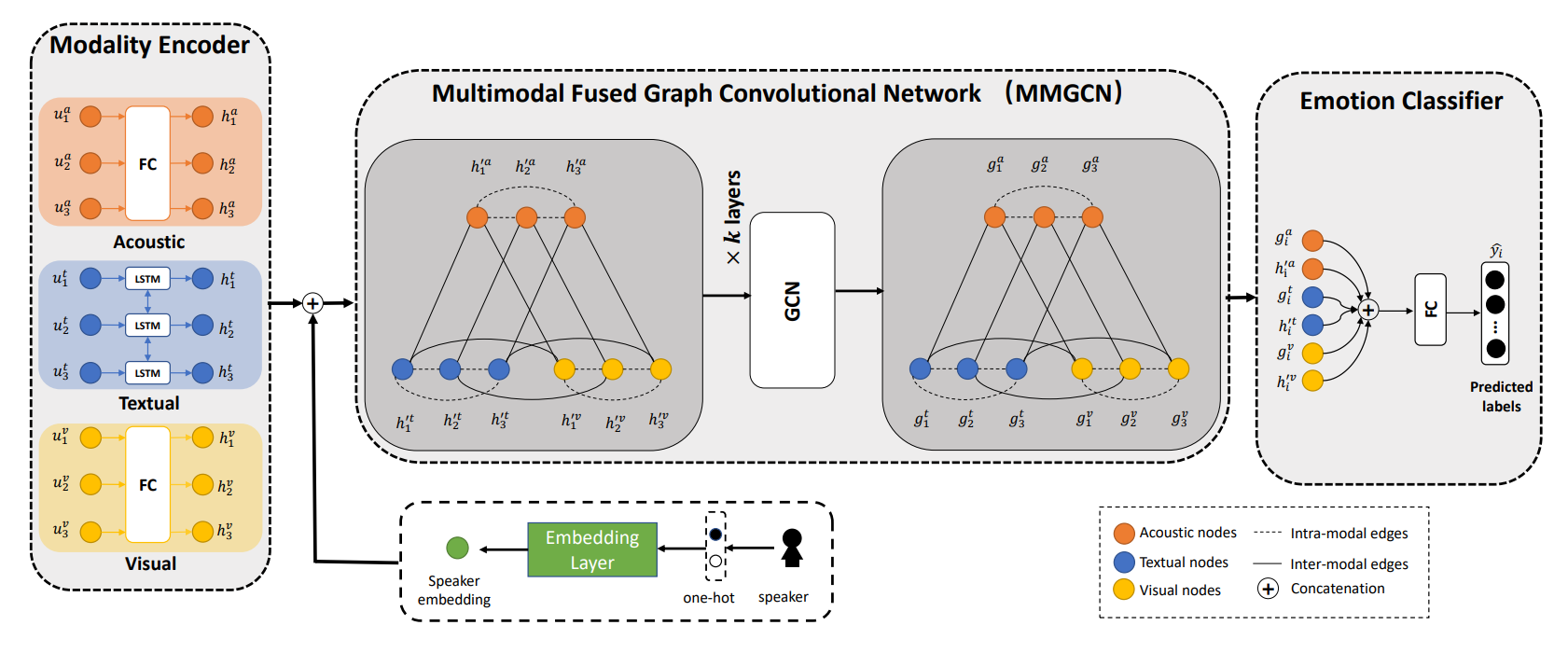
MMGCN——Multimodal Fused Graph Convolutional Network
Motivation:先前的RNN-based模型不能有效捕捉长距离信息和复杂的语境关系,而DialogueGCN展现了GNN在ERC中的潜力,因此提出MMGCN使用GNN处理多模态ERC
Method:
Modality Encoder模块分别使用LSTM和全连接网络对文本、听觉/视觉特征进一步编码,结果记为$h_i={h_i^a,h_i^v,h_i^t}$
Speaker Embedding模块用于用于编码speaker信息,记$s_i\in R^m$为表示speaker的one-hot向量,则Speaker Embedding为$S_i=W_ss_i+b_i^s$
MMGCN按如下方式建图
每个utterance由三个节点$v_i^a,v_i^v,v_i^t$表示,初始特征分别为$h_i^{‘a}=[h_i^a,S_i],h_i^{‘v}=[h_i^v,S_i],h_i^{‘t}=[h_i^t,S_i]$
边有两种类型:(1) 模态相同的两节点间建边,边权为$A{ij}=1-\frac{\arccos(sim(n_i,n_j))}{\pi}$;(2) 同一utterance的不同模态的节点间建边,边权为$A{ij}=\gamma(1-\frac{\arccos(sim(n_i,n_j))}{\pi})$
其中$sim()$为余弦相似度,$\gamma$为超参,边均为无向边
图的处理采用GCN,为了加深深度,MMGCN采用residual connection的思想将$H^{(0)}$连接到每层GCN,表达式为
其中$\tilde{\mathcal{P}}=\mathbf{\tilde{D}}^{-\frac{1}{2}}\mathbf{\tilde{A}}\mathbf{\tilde{D}}^{\frac{1}{2}}$
最后将GCN的输入和输出进行拼接$e_i=[h_i’,g_i]$,输入MLP层进行分类
MM-DFN
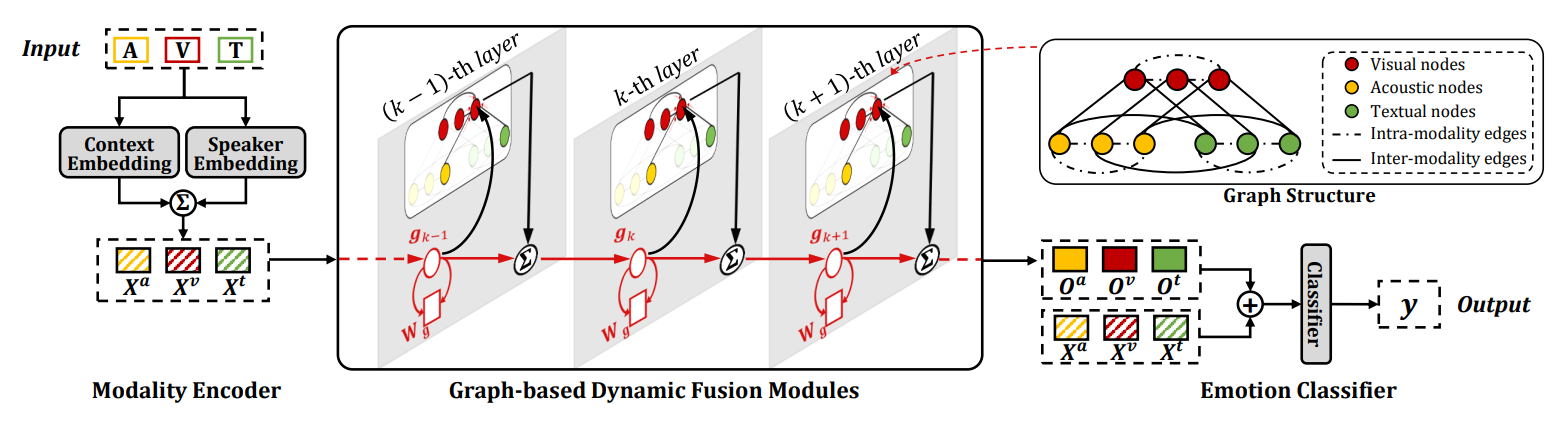
MM-DFN——Multimodal Dynamic Fusion Network
Motivation:认为先前的GNN模型在多模态融合过程中容易积累冗余信息,因此借鉴LSTM将门控思想加入GNN
Method:
Context Embedding模块分别使用BiGRU和全连接网络对文本、听觉/视觉进行编码,结果记为$c_i={c_i^a,c_i^v,c_i^t}$
Speaker Embedding使用BiGRU编码speaker信息,表达式为
MMDFN的建图方式与MGCN基本一致
每个utterance对应于表示三个模态的三个节点,初始特征分别为$x_i^{\delta}=c_i^{\delta}+\gamma^{\delta}s_i^{\delta},\delta\in{a,v,t}$
然后模态相同的两节点间建边, 同一utterance的不同模态的节点间建边,边权均为$A_{ij}=1-\frac{\arccos(sim(n_i,n_j))}{\pi}$
MMDFN将LSTM的门控思想加入到了GCN中,表达式为
其中$\boldsymbol{\Gamma}{u}^{(k)},\boldsymbol{\Gamma}{f}^{(k)},\boldsymbol{\Gamma}_{o}^{(k)}$分别为更新门、遗忘门和输出门
多层GCN的堆叠方式与MMGCN相同
其中$\mathbf{H}^{\prime(k)}=\mathbf{H}^{\prime(k)}+\mathbf{g}^{k}$
最后的分类层同样是将GCN输入输出进行拼接后输入MLP
COGMEN
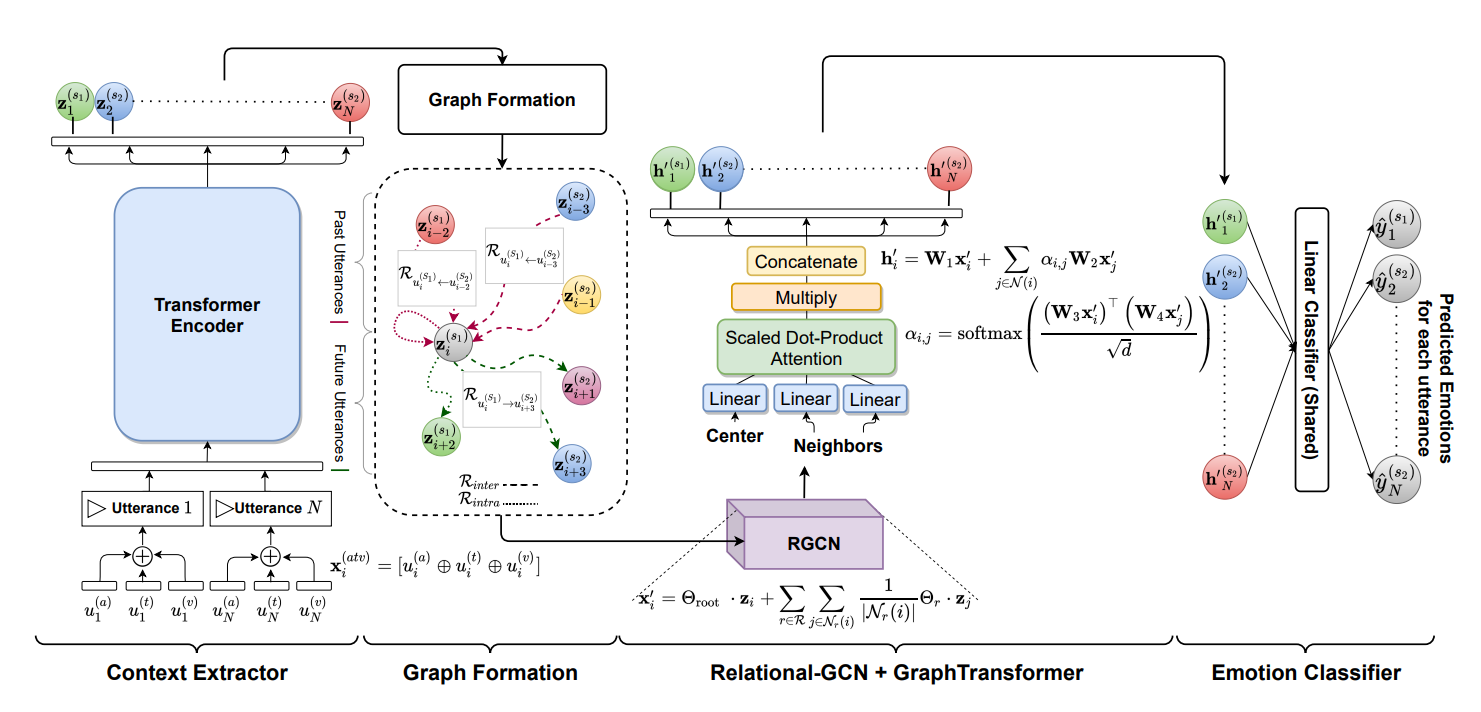
COGEM——COntextualized GNN based Multimodal Emotion recognitioN
Motivation:尝试用Transformer和GraphTransformer捕捉更丰富的信息,具体来说,编码阶段用Transformer Encoder代替先前的序列模型,更有效地捕捉全局信息;图处理阶段依次用RGCN和GraphTransformer进行处理,有效捕捉局部信息
Method:
Context Extractor将每个$u_i$对应的三个模态特征进行拼接得到$x_i=concat(u_i^a,u_i^v,u_i^t)$,并使用Transformer Encoder处理$x_i$序列得到每个utterance的特征$z_i$
之后按如下方式建图
每个utterance作为一个节点,初始特征为$z_i$
建边方法及边的关系集合与DialogueGCN一致:采用窗口法建边,每个$u_i$只与过去的$p$个及未来的$f$个utterance相连;关系有两大类,speaker两两之间构成一个关系,某条边的出点$u_i$和入点$u_j$的相对位置构成一个关系,共$2M^2$种不同关系
例如,假设对话只有2个speaker,令$U^{S_i}={u^{S_i}_1,\cdots\,u^{S_i}_n}$表示第$i$个speaker的utterance集合,对于$u^{S_1}_i$则有如下的边
这些边可视为建模了两类依赖:(1) $R{intra}\in {U^{S_i}\to U^{S_i}}$用于建模intra-speaker依赖 (2) $R{inter}\in {U^{S_i}\to U^{S_j}},i\neq j$用于建模inter-speaker依赖
COGMEN依次使用RGCN和GraphTransformer对构建的图进行处理,最后再输入MLP层进行分类
GCNet
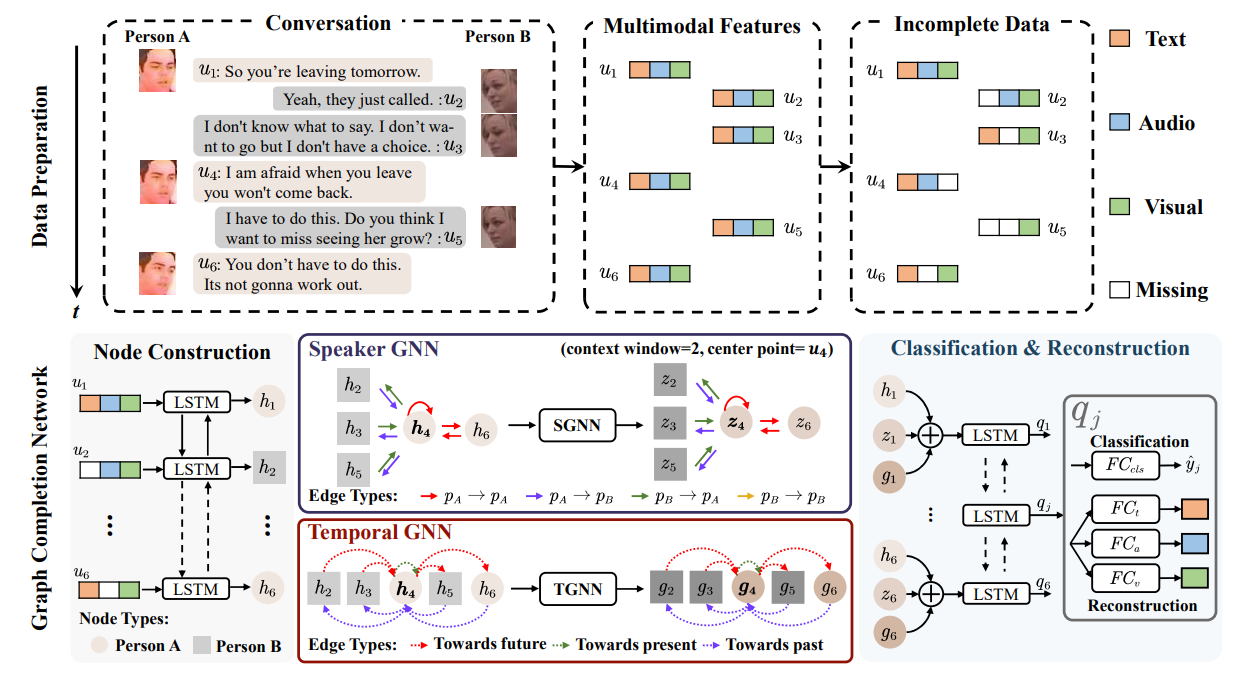
GCNet——Graph Completion Network
Motivation:处理现实中输入模态缺失问题
method:
假设训练数据集是模态完整的,为模拟模态缺失场景,首先对训练集中每个$u_i$进行随机模态丢弃,但保证每个$u_i$至少有一个可用模态,其中确实模态为全0向量
将每个$u_i$的三个模态特征进行拼接,并使用BiLSTM进行编码,得到$h_1,\cdots,h_N$作为图节点的初始特征
边的构建同样采用窗口法,每个节点$u_i$只与前后$w$个utterance相连
GCNet只构建一个图,但定义两个不同的关系集和,分别使用两个不同的RGCN进行处理
第一个RGCN称为Speaker GNN (SGNN) ,用于建模speaker dependency,speaker两两之间的连边构成其上的关系集和,共$M^2$种,例如边$e{ij}$的关系类型为$(p{\phi(ui)},p{\phi(u_j)})$
第一个RGCN称为Temporal GNN (TGNN) ,用于建模temporal dependency,其上的关系集和为${past,present,future}$,用于表明边的出点和入点的相对位置关系
容易看出其实关系类型还是DialogueGCN的做法
记SGNN和TGNN节点$i$的输出分别为$z_i,g_i$,GCNet对$h_i,z_i,g_i$进行拼接并输入BiLSTM进行处理得到$q_i$
特别的,为了有效建模缺失的模态,GCNet使用了同时使用了交叉熵损失和重建损失,其中重建损失表示为
其中$\lambda$表示模态是否缺失,$\lambda=1$是表示未确实,$\lambda=0$表示缺失,因此重建损失只评价确实模态的重建
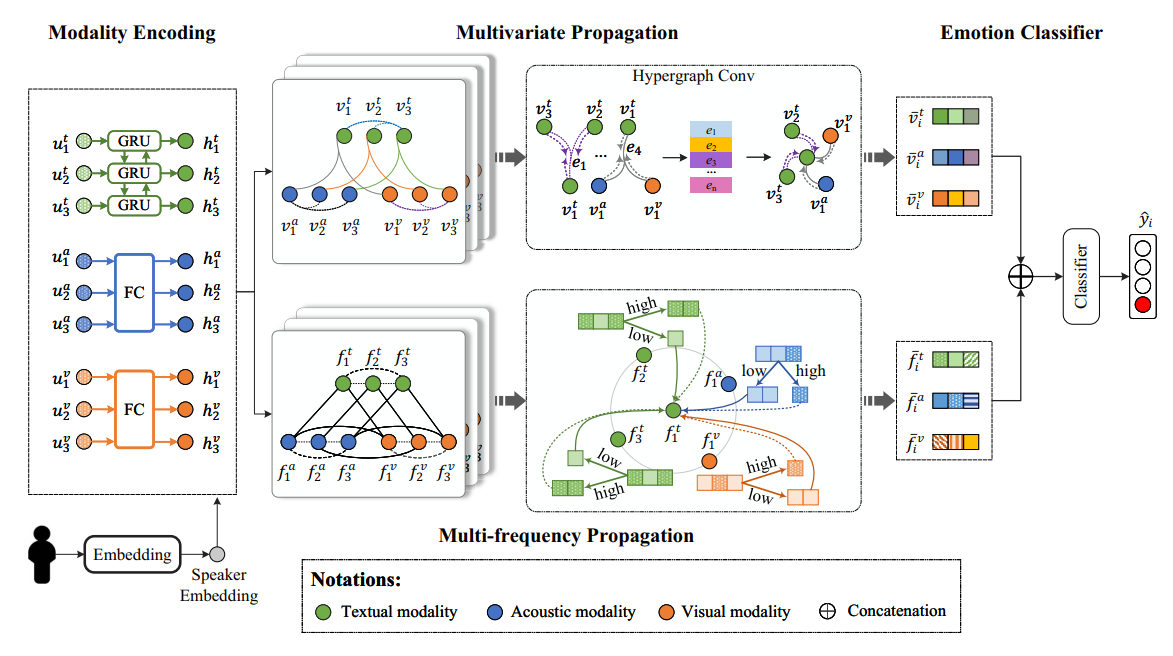
M^3Net
M^3Net——Multivariate Multi-frequency Multimodal Graph Neural Network
Motivation:认为先前的GNN模型对对话中的多元关系和高频信息的利用不足,因此M3Net使用两个GNN分别捕捉multivariate和multi-frequency信息
method:
模态特征编码与MMGCN相同,使用LSTM和FC分别对模态特征进行处理,并与speaker embedding相加