
DialogueGCN
DialogueGCN是最早将GNN引入对话处理领域的研究之一
这篇论文关注的具体问题是对话情感识别(ERC, Emotion recognition in conversation)
与孤立文本的情感识别不同,ERC需要捕捉长距离的语境信息,以及其他复杂的上下文依赖,例如不同speaker之间的关系,先前的RNN-based ERC模型很难有效捕捉这些信息
为解决这个问题,DialogueGCN用图结构进行对话建模,并使用GNN进行处理
具体来说,DialogueGCN主要关注两种类型的上下文建模:sequential context 和 speaker-level context
设一段对话包含来自$M$个speaker $p1,\cdots,p_M$的$N$段utterance $u_1,\cdots,u_N$,每段utterance有一个对应的情感标签$y_i$,共有$C$个不同的标签,$p{s(u_i)}$表示$u_i$对应的speaker,$u_i\in R^d$为已提取的特征表示
DialogueGCN结构如图所示
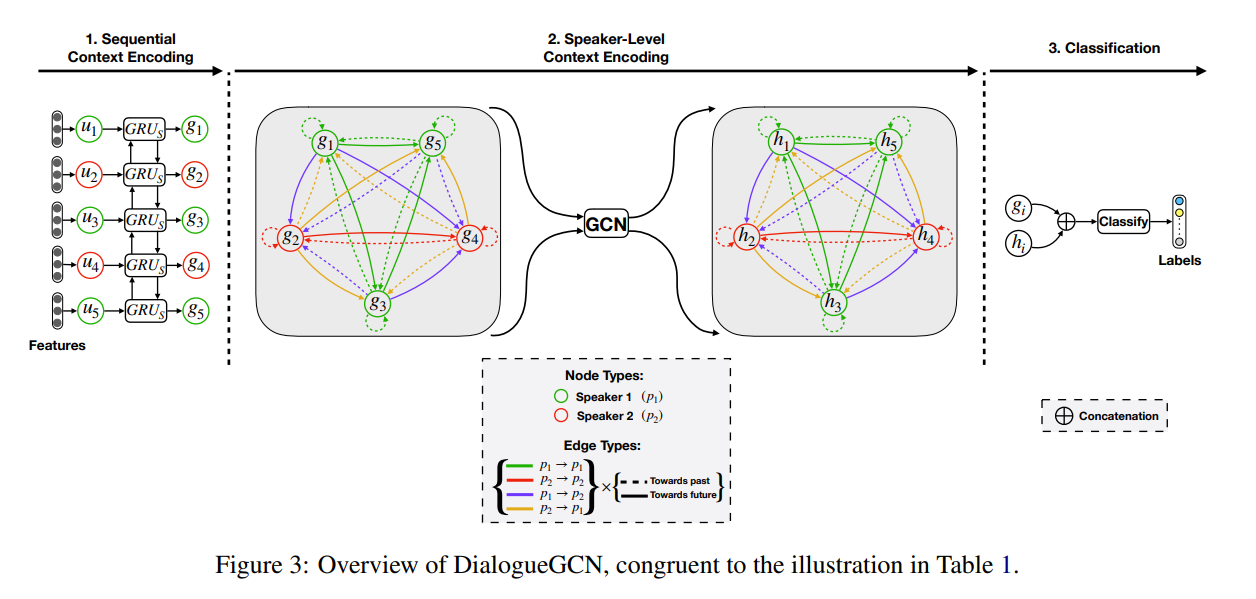
为了建模sequential context,首先使用双向GRU将$u_1,\cdots,u_N$编码为$g_1,\cdots,g_N$
为了建模speaker-level context,接下来需要构建一个无向图$G=(V,E,R,W)$来表示对话关系,其中$V,E,R,W$分别为顶点集、边集、关系集(用于RGCN)和边权集
顶点:对话中每个utterance $u_i$被表示为一个顶点$v_i\in V$,以$g_i$作为其初始特征
边:边采用窗口法构建,对每个顶点$vi$,并分别与其过去的$p$个utterance $v{i-1},\cdots,v{i-p}$和未来的$f$个utterance $v{i+1},\cdots,v_{i+f}$建边,这些边均为双向的有向边,最后一个建立到自身的环
边权:边权使用基于相似度的注意力机制确定,任意节点$v_i$所有入边的边权和为1,即对于节点$v_i$有
关系:每两个不同的speaker之间构成一类关系,用于建模speaker dependency;utterance之间的相对位置构成一类关系,表明某条边的源$u_i$是否在汇$u_j$之前,用于建模Temporal dependency,以上总共构成$2M^2$种不同关系
完成建图后,使用RGCN进行两步处理,公式分别为
最后分类层将$h_i^{(2)}$和$g_i$进行拼接后输入MLP进行分类