HRED for Dialogue System
相关论文:
A Hierarchical Recurrent Encoder-Decoder for Generative Context-Aware Query Suggestion
首次提出HRED,用于Web Query Suggestion
Building End-to-End Dialogue Systems Using Generative Hierarchical Neural Network Models
将HRED引入Dialogue Syetem领域,建立端到端模型
A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues
VHRED,使用VAE思想,利用隐变量传递高层次信息,增强生成多样性
Modeling Semantic Relationship in Multi-turn Conversations with Hierarchical Latent Variables
CSRR,与VHRED类似,使用VAE用一个隐变量概括discourse-level信息
Hierarchical Recurrent Attention Network for Response Generation
HRAN,为HRED引入Attention机制
ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation
ReCoSa,用Self-Attention替代RNN with attention
问题定义
我们以Dialogue System为例来说明HRED,几篇论文使用的符合都不相同,此处先统一定义
一个dialogue由来自两个说话人的$N$段utterance组成,即$D={U_1,…,U_N}$
每个$Un$包括$T_n$个token,即$U_n={w{n,1},…,w_{n,T_n}}$,每个token可能是字词,也可能是标点
Dialogue System的目标是根据历史对话$U1,…,U{n-1}$生成下一个utterance $Un$,即建模$P{\theta}(w{n,m}|w{n,<m},U_{<n})$
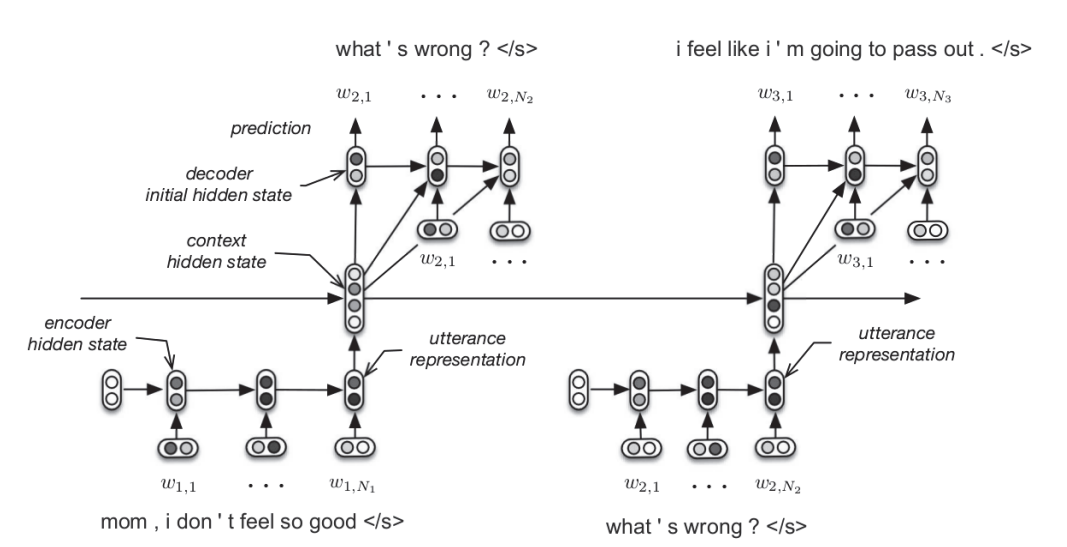
HRED
与传统的seq2seq问题(例如机器翻译)不同,seq2seq只需要考虑当前输入的句子,而Dialogue System还需要考虑历史对话(历史输入输出),也即上下文context
HRED (Hierarchical Recurrent Encoder-Decoder) 的引入就是为了解决对context建模的问题
HRED仍然是Encoder-Decoder结构,包含三部分
Encoder RNN:encoder第一层,将$U_1,…,U_n$分别编码为utterance vector$h^{enc}_1,…,h^{enc}_n$
Context RNN:encoder第二层,将utterance vector序列 $h^{enc}_1,…,h^{enc}_n$ 编码为一个context vector $h^{con}_n$
Decoder RNN:decoder将上一个句子的utterance vector $hn^{enc}$ 作为initial state,将context vector $h^{con}_n$ 与每个word embedding拼接后作为输入,生成$U{n+1}$
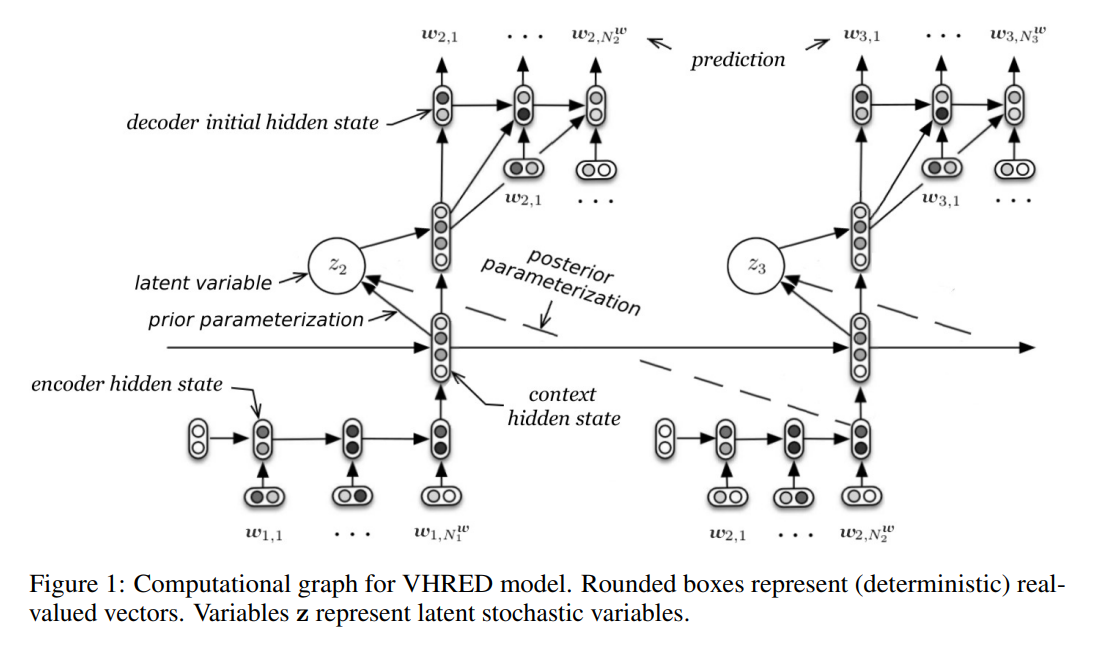
VHRED
对于Dialogue Sytem,传统的Encoder-Decoder和HRED都存在一个问题——生成的对话缺乏多样性
其原因是decoder以扁平的、序列化的方式生成下一个token(flat sequential generation process) ,也即每个单词的生成只条件依赖之前的单词,其直接表现就是模型倾向于生成短的安全回答
VHRED (Latent Variable Hierarchical Recurrent Encoder-Decoder) 的思想是为每个utterance $n=1,…,N$引入一个隐变量$z_n\in R^{d_z}$,生成$U_n$时使用如下的两级生成
其中$\mu\in R^{d_z}, \Sigma \in R^{d_z\times d_z}$且$\Sigma$为对角阵
通过将context vector $hn^{con}$输入一个两层前馈网络,然后应用两个不同的矩阵乘,可以分别获得$\mu{prior},\Sigma_{prior}$(注意$\Sigma$需要一个softplus激活保证为正数)
我们可以通过优化变分下界学习后验$Q{\psi}(z_n|U{< n}, Un)$,以此近似$P{\theta}(zn|U{<n})$
具体来说,在训练阶段,将context vector $hn^{con}$ 与utterance vector $h{n+1}^{enc}$ 拼接后输入一个两层前馈网络,然后应用两个不同的矩阵乘分别获得$\mu{posterior},\Sigma{posterior}$,并使用其采样$z_n$
而在测试阶段,则使用$\mu{prior},\Sigma{prior}$采样$z_n$
VHRED的思路和VAE很相似,相当于对历史utterance进行压缩再重建
$z_n$可以为decoder提供话题、情感、目标等多种高层信息,因此显著提高了生成的丰富性
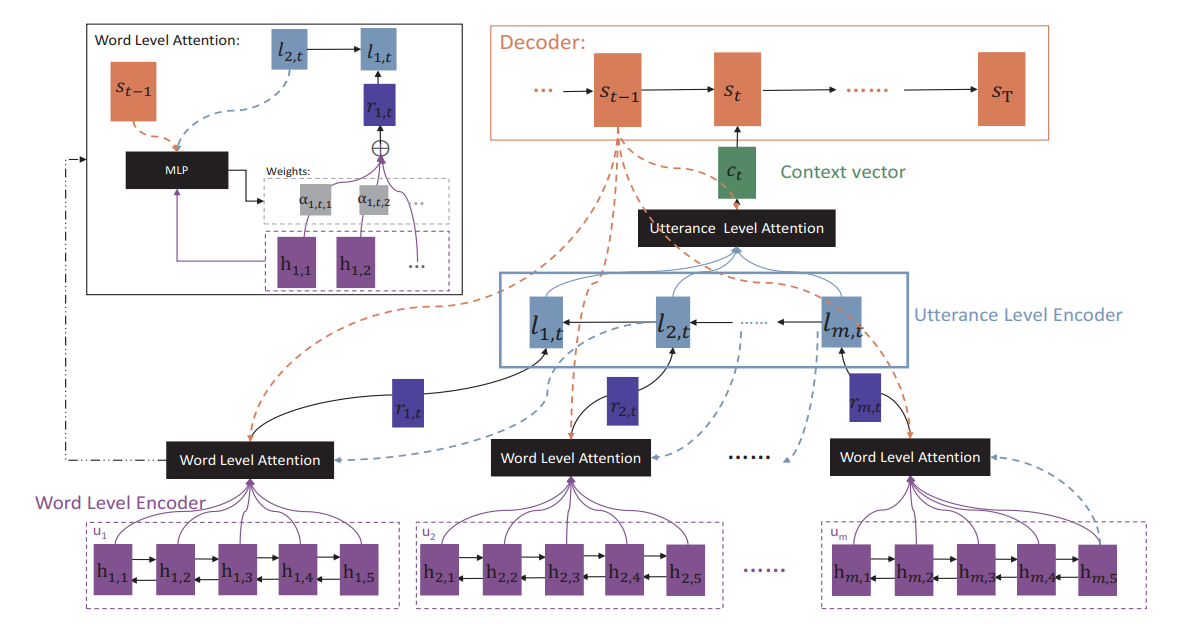
HRAN
HRED和VHRED都专注于对context层级进行建模,而没有对历史对话中不同utterance的重要性进行建模,容易想到可以引入attention机制来解决这个问题,于是Xing et al.提出了HRAN (Hierarchical Recurrent Attention Network)
HRAN的结构如图所示,假设当前decoder正在生成第$n$个utterance的第$t$个token $w_{n,t}$
Word Level Encoder:使用双向GRU,将每个$Ui=(w{i,1},…,w{i,T_i}),\ i=1,2,…,n-1$分别编码为隐状态序列$h_i=(h{i,1},…,h{i,T_i})$,使用attention分别计算其加权和 $r^t_i=\sum{j=1}^{Ti}\alpha^t{i,j}h_{i,j}$
Utterance Level Encoder:使用逆向GRU,以序列$r^t=(r^t1,…,r^t{n-1})$作为输入,输出隐状态序列$l^t=(l^t1,…,l^t{n-1})$,再次使用attention计算加权和 $ct=\sum{j=1}^{n-1}\beta^t{j}l^t{j}$
Decoder:将$ct$与$w{n,t-1}$的embedding进行拼接作为输入,生成$w{n,t}$的预测值$s{n,t}$
其中对Utterance Level Encoder的attention权重矩阵仅由Decoder的隐状态序列确定,与普通attention一致
对Word Level Encoder的attention略有不同,其权重矩阵由Utterance Level Encoder和Decoder共同决定,具体地,我们需要拼接相应隐状态$h,l,s$并输入一个MLP,并通过softmax激活得到权重矩阵
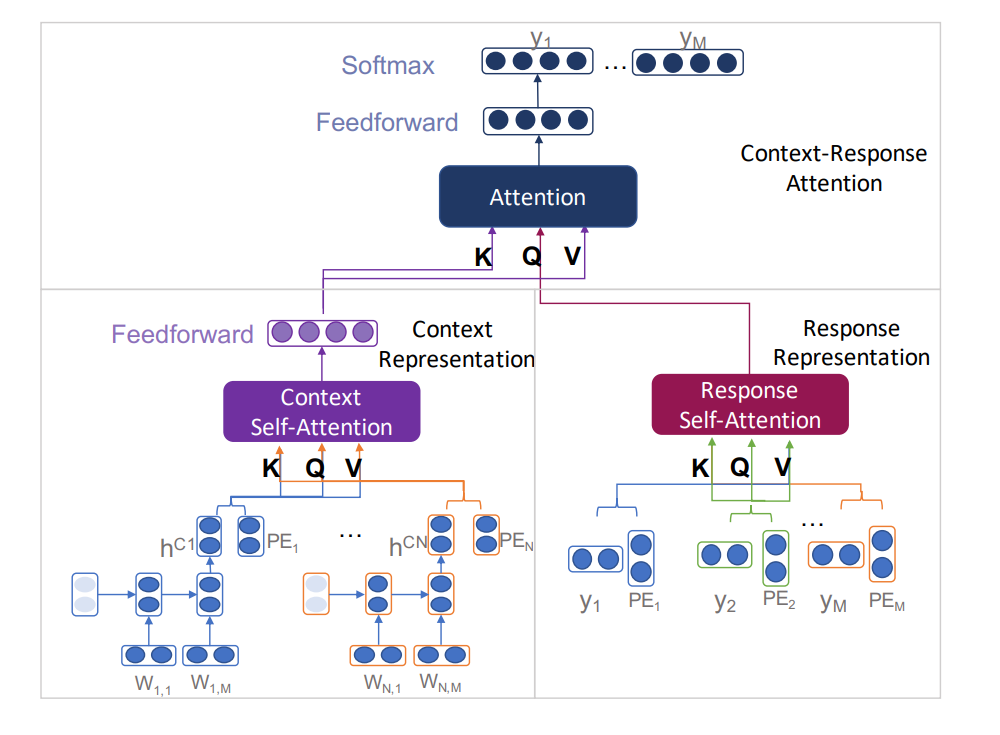
ReCoSa
Transformer中self-attention的成功启发了很多新研究,而ReCoSa (Relevant Context Self-Attention Model) 就是将其引入到Dialogue System的成果
相较于HRAN,使用self-attention机制的ReCoSa能更好地捕捉到长距离依赖信息
如图所示,ReCoSa包含三个部分
Context Representation Encoder:
先使用LSTM将每个历史utterance $U1,…,U{n}$分别编码为utterance vector $h1,…,h{n}$,并将其与position embedding进行拼接得到${(h_1,P_1),…,(h_n,P_n)}$
然后使用multi-head attention进行self-attention处理(即Q=K=V),最后经过一个MLP得到context representation
Response Representation Encoder:
将相应的应答$U_{n+1}$与position embedding相加,经过self-attention得到response representation
特别的,训练时需要使用future mask,防止self-attention注意到未来的信息
Context-Response Attention Decoder:
令$K=V$为context representation,$Q$为response representation,进行multi-head attention处理,最后经过MLP并softmax激活得到输出
容易看出来其整体就是Transformer的结构