CLIP论文解读
论文链接:Learning Transferable Visual Models From Natural Language Supervision
引言
近年来一系列直接利用raw text进行预训练的模型为NLP领域带来了革命性发展
这些预训练模型的成功表明,对于预训练模型来说,利用整个web尺度收集的文本进行聚合监督(aggregate supervision)的效果已经超过了使用众包标注的高质量数据集进行训练的效果
the aggregate supervision accessible to modern pre-training methods within web-scale collections of text surpasses that of high-quality crowd-labeled NLP datasets
然而在CV领域,使用众包标注的数据集(例如ImageNet)进行预训练仍然是标准做法
我们自然会思考,直接使用web收集的大尺度文本集能否为CV带来同样的突破
对于从文本中学习图像表达(image representation)的问题,先前的研究中VirTex、ICMLM和ConVIRT分别证明了基于Transformer的语言模型、Masked Language Modeling和对比学习(contrastive learning)在该问题中的潜力
但是这几个模型的表现仍然低于SOTA,其关键原因是尺度差距
该论文的目标就是研究使用大尺度文本集对图像模型进行监督训练并消除这个差距
其采用的模型是简化版的ConVIRT,称为CLIP,即Contrastive Language-Image Pre-training
大数据集构建
先前研究使用的图像语义理解数据集主要有3个:MS-COCO、Visual Genome、YFCC100M
MS-COCO和Visual Genome都是质量很高的众包标注数据集,但规模很小,只有约10万张图片;YFCC100M有100M的图像,但质量参差不齐,从中筛选出有英文描述的图像后只剩约15M,与ImageNet大小相当
如引言所述,网络上有海量的带有自然语言描述的图像,因此论文作者从各个网络公共资源平台上获取了共400M个(image, text)对构建了一个新数据集,称为WIT,即WebImageText
构建过程中,为了覆盖尽可能广泛的视觉概念,作者建立了一个大小约50万的查询(query)集(根据wiki高频词+bi-gram数据增强+WordNet建立),搜索过程必须保证(image, text)对中的text包含某个query
此外为了平衡数据集,每个query至多包含20000个(image, text)对
预训练方法选择
先前的研究表明对比目标函数(contrastive objectives)的表现可以超越等价的预测目标函数(predictive objective)
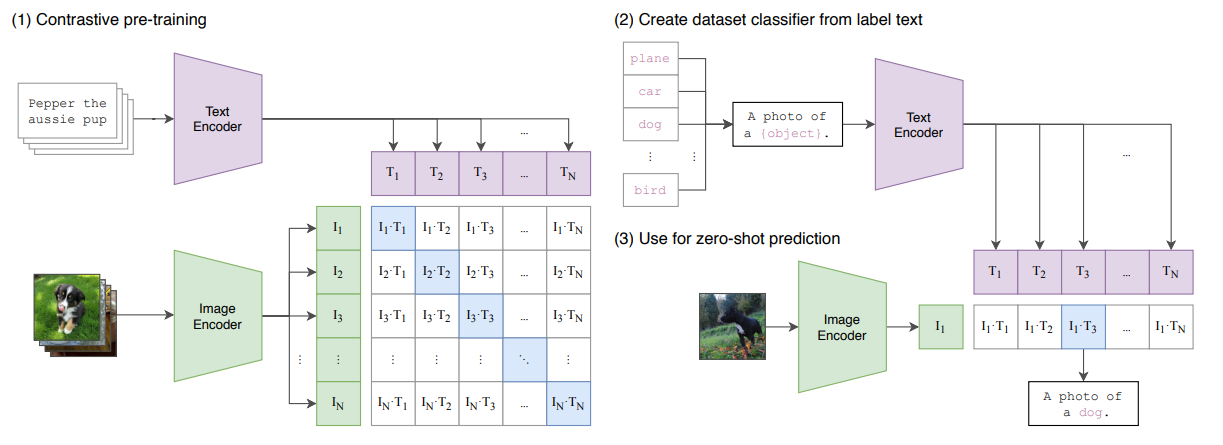
论文利用对比学习的思路提出了一种更简单的预测任务:将一段text作为整体预测其与哪个image匹配
即给定$N$个(image, text)对,CLIP的目标是从$N\times N$个可能的(image, text)对中找到实际出现的
为了完成这个任务,CLIP同时训练一个image encoder和一个text encoder,对于$N$个真实(image, text)对,CLIP需要最大化其对应的image embedding和text embedding之间的余弦相似度,对于$N^2-N$个错误(image, text)对,则最小化
上述最大/最小化通过一种对称交叉熵(symmetric cross entropy)实现
如下图伪码所示,矩阵$I_e\cdot T_e^T$是$N^2$个对的余弦相似度矩阵,它被分别按行、列视为一个batch的N分类概率输出,通过优化其与 labels=[1,2,…,N] 的交叉熵,间接实现最大化矩阵对角元素
上述预训练方法称为Multi-Class N-pair Loss

模型选择
对于image encoder,论文使用了两种模型
第一种是ResNet50,其中做了一些改进,包括ResNetD、antialiased rect-2 blur pooling、全局池化变为attention池化
第二种是ViT,只做了一些小改动,embedding输入Transformer前加了一个layer normalization
对于text encoder,论文采用了Transformer,输入文本上使用了BPE,文本序列前后分别添加了[SOS]和[EOS] token,文本representation通过[EOS]对应的输出获得
对于image encoder,缩放采用EfficientNet的方法,对于text encoder,则只缩放宽度,论文称CLIP的表现对text encoder并不敏感
CLIP使用
对于下游任务,CLIP重新利用预训练获得的能力,即预测某个图像和某段文本是否为一对的能力
具体来说,对一个分类数据集,我们将所有class的名字分别作为text,让CLIP预测输入图像与哪个最有可能是一对
当然,text也可以进一步加上prompt,例如前面图中的 “A photo of [class]”
显然这个过程是一种zero-shot迁移
Zero-Shot分析
CV领域中zero-shot通常指图像分类中对未见过的标签具有泛化能力
CLIP论文中zero-shot的概念被扩展为对未见过的数据集的泛化能力
已有的无监督CV研究主要关注于模型的表示学习(representation learning)能力,而论文将zero-shot迁移学习作为一种测量模型任务学习(task learning)能力的方法
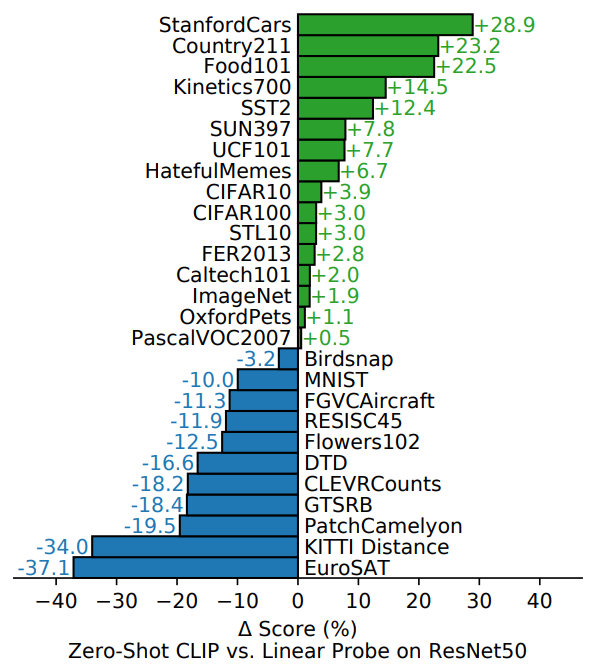
首先是Zero-Shot CLIP与现成有监督baseline(ResNet50顶层加上一个分类器进行linear probe)的对比
- CLIP提升最大的是STL10数据集,这是一个为无监督学习设计的标注数据非常有限的数据集,CLIP没有进行任何训练,达到了99.3%的准确率,成为新SOTA
- 细粒度分类任务上有很多不同结果,Stanford Cars和Food101数据集上Zero-Shot CLIP超过ResNet 20%,Flowers102 and FGVCAircraft数据集上则低于ResNet 10%
- 对于一般性分类数据集,例如ImageNet, CIFAR10, PascalVOC2007,两者结果相近,Zero-Shot CLIP有轻微优势
- 对于动作识别,在Kinetics700, UCF101数据集上Zero-Shot CLIP超过ResNet很多(论文推测原因是自然语言为涉及动词的视觉概念提供了更多监督)
- CLIP在专业图像、复杂图像或抽象任务上表现较差,例如卫星图像识别(EuroSAT, RESISC45)、肿瘤探测(PatchCamelyon)、合成场景目标计数(CLEVRCounts),还有自动驾驶相关任务,例如GTSRB、KITTI Distance
- 需要注意的是,对于困难任务,目前并不清楚zero-shot迁移(相对于few-shot迁移)是否是一个好的评估方法,因为这些知识很难从预训练中获得,就像大多数普通人也无法对肿瘤进行分类
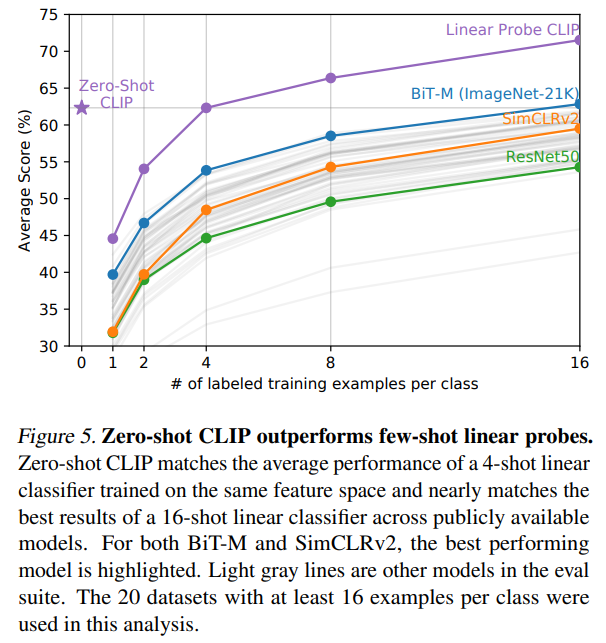
接下来是Zero-Shot CLIP与一些Few-Shot方法的对比
zero-shot CLIP与4-shot CLIP表现相近
论文推测的原因是,zero-shot CLIP分类器可以通过自然语言直接联系视觉概念,而监督方法只能间接从样本中间接推理视觉概念,一个图像往往包含多个视觉概念,few-shot很难全部学到
zero-shot CLIP与16-shot有监督模型表现相近
Representation学习分析
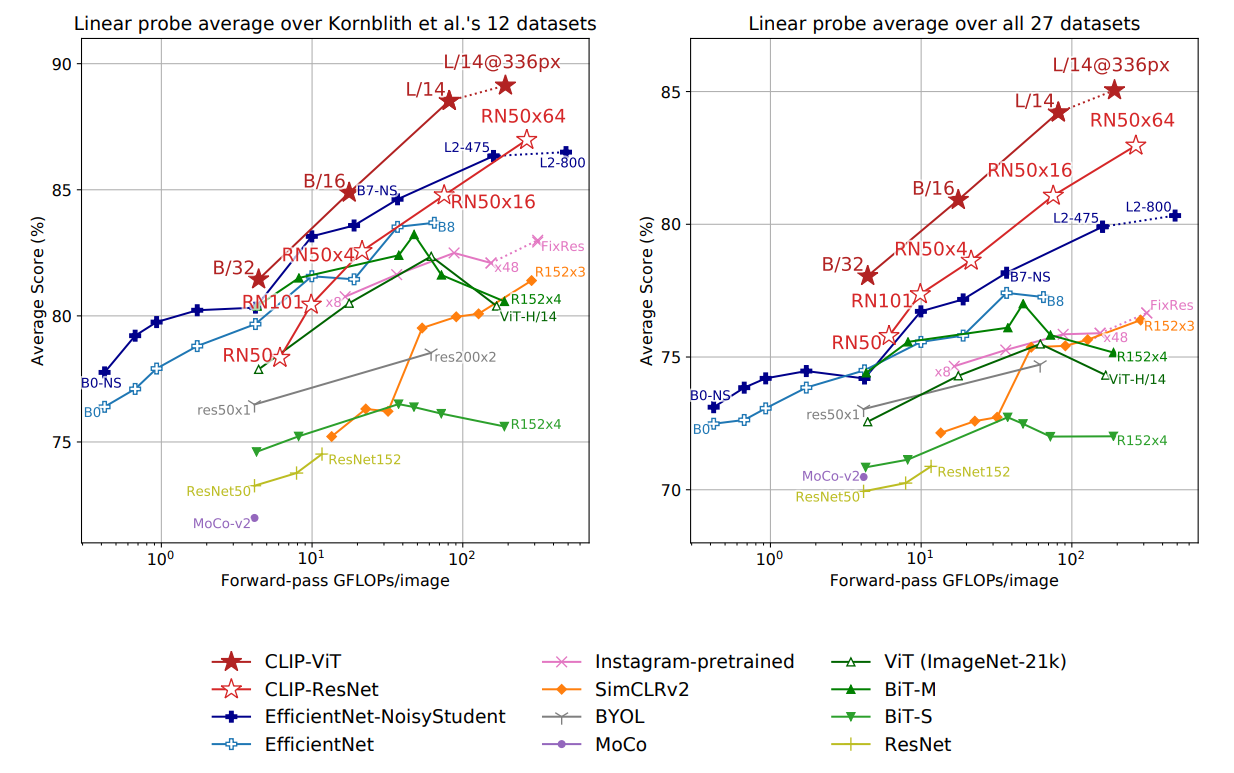
下图展示的是CLIP与其他模型的Linear Probe Evaluation对比
左图是12个来自论文《Do better imagenet models transfer better?》的数据集的对比,其中最大的CLIP-ResNet在效率和准确率上都轻微胜过目前最好的模型,而CLIP-ViT进一步提高了约3倍
右图是更广泛的27个数据集上的对比,可以明显发现CLIP在效率和准确率上都有了更大的提升,说明CLIP相比已有的模型能学得更广泛的任务
这可以认为是Kornblith论文所说的selection bias的一种形式
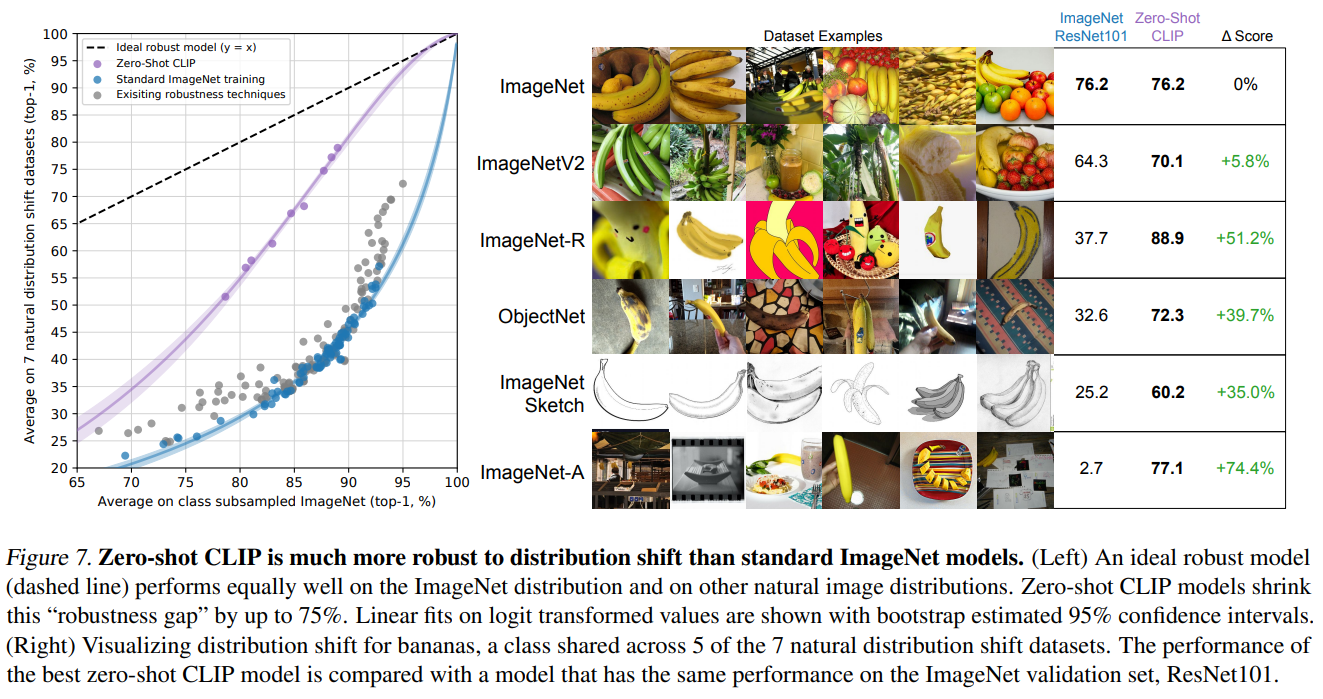
Distribution Shifts鲁棒性
Taori等人的论文提出鲁棒性分析应分为effective robustness和relative robustness
这里CLIP论文的解释有点难理解,所以直接引用Taori论文的定义
设$\rho(f)$是模型$f$的effective robustness,则
$acc_1,acc_2$分别是模型在标准测试集和有分布偏移的测试集上的准确率
对于给定的在标准测试集上的准确率$x$,$\beta(x)$表示偏移测试集上的baseline准确率
也即effective robustness衡量有分布偏移的数据集上的预期之外的准确率提升
设$f’$是从$f$导出的带有鲁棒性干涉(robustness intervention)的模型,则relative robustness为
从直观上考虑,zero-shot CLIP没有使用某个特定分布进行训练,所以也就不会利用这个分布中的虚假相关性或模式,进而zero-shot CLIP应该拥有更高的effective robustness
Figure7展示了zero-shot CLIP与ImageNet model针对自然分布偏移的效果对比,可以明显发现CLIP effective robustness非常高,这也验证了大规模任务和数据集无关预训练+zeros-shot迁移这条方向的潜力