ViT——Vision Transformer论文解读
论文地址:An Image is Worth 16X16 Words-Transformers for Image Recognition at Scale
Introduction
基于self-attention的Transformer系模型已经逐渐成为NLP领域的首选
其主要方法是在大语料库上进行预训练并在特定任务的小数据集上进行微调
得益于Transformer的高效性和可扩展性,前所未有的大模型训练成为可能,并且仍没有饱和的迹象
在CV领域,一些研究受到Transformer的启发而尝试将self-attention与CNN结合或完全移除CNN,但这些研究使用的特制的attention模式导致其不能有效利用硬件加速器
因此,在大尺度图像识别中,传统的类ResNet模型仍是state of the art
综上所述,这篇论文的目的就是对标准Transformer能否直接应用于图像进行试验,称为Vision Transformer, ViT
具体来说,论文中直接将图片分为多个patch,并将这些patch的embedding序列直接作为ViT输入,也即直接将图像patch当作NLP应用中的token对待
实验结果是,在中等大小数据集(如ImageNet)上,ViT比ResNet低了几个百分点的准确率,但在大数据集上,ViT取得了非常好的效果
Vision Transformer
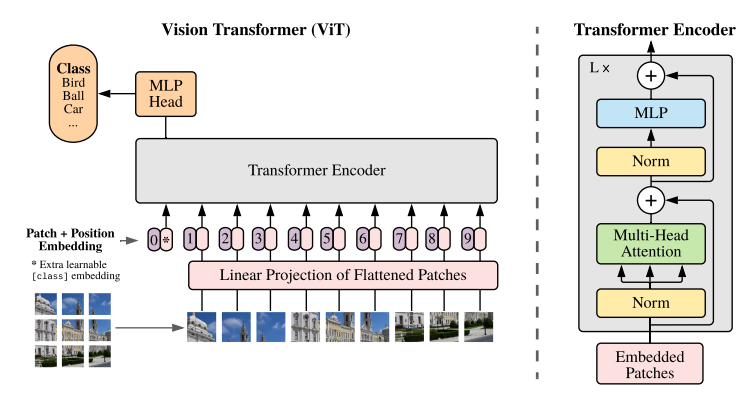
ViT的结构如下图所示
Transformer原本接受的是1D输入,为了处理2D图像,首先将图像$x\in R^{H\times W\times C}$转为为展平的patch的序列$x_p\in R^{N\times(P^2\cdot C)}$,其中$(P,P)$是每个patch的分辨率,且$N=HW/P^2$是patch个数,也是输入序列长度
之后用一个线性全连接层将patch序列映射到$D$维,即$shape=(N, D)$,称其为patch embedding
与BERT的[CLS] token类似,patch embedding序列前面加入一个可学习的embedding $z0^0=x{class}$,其对应的Transformer输出$z^0_L$用于继续输入MLP做分类
patch embedding还需要与position embedding相加,论文使用了1D position embedding,因为实验结果表明2D position embedding相比1D并没有什么效果提升
相比CNN,ViT的归纳偏好更少
CNN中,局部性、二维邻域结构、平移等变形等固化在整个模型的每一层(翻译不一定准确,见以下原文)
In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model
而在ViT中,只有MLP层具有局部性和平移等变形,而self-attention是全局的
对于二维邻域结构,ViT只在分割patch时和fine-tune中调整positon-embedding时使用
对于fine-tuning,ViT可以处理任意长的序列(也即任意大分辨率的图像),但这样预训练的positon-embedding就会变得没有意义,因此需要根据patch在原图像中的位置对预训练的positon-embedding进行2D插值,也即引入了二维邻域结构
此外,ViT的原始图片输入也可以替换为CNN的特征图输入,构成一个混合模型(Hybrid Architecture)
Experiments
Datasets & Model Variants
为了测试模型可扩展性,论文使用以下几个不同大小的数据集进行预训练
ILSVRC-2012 ImageNet:图像数1.3M,类别数1k
ImageNet-21k:ImageNet的超集,图像数14M,类别数21k
JFT:图像数303M(高分辨率),类别数18k
进行迁移的下游benchmark如下,预处理方法与BiT论文相同
- ImageNet原始验证labels和经过清洗的ReaL labels
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
此外还有google的VTAB,用于评估低数据量下不同任务的迁移学习,每个下游任务只有1000个样本
VTAB有19个任务,可以分为三类:1.自然图像:例如上述数据集 2. 专业图像:例如医药或卫星图像 3.结构化图像:需要几何理解,例如定位
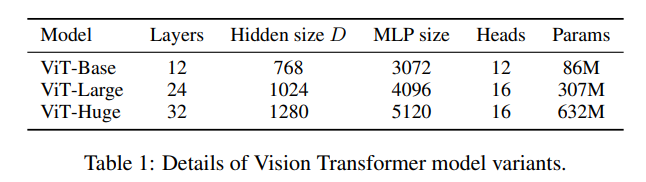
测试的ViT模型如下图所示,Base和Large基于BERT的配置,Huge是新增的更大的模型
后面用简记形式表示不同模型,例如ViT-L/16表示Large模型,输入patch尺寸为16×16
注意Transformer的输入序列长度与patch尺寸平方成反比,因此patch尺寸越小的模型计算成本越高
Comparison to SOTA
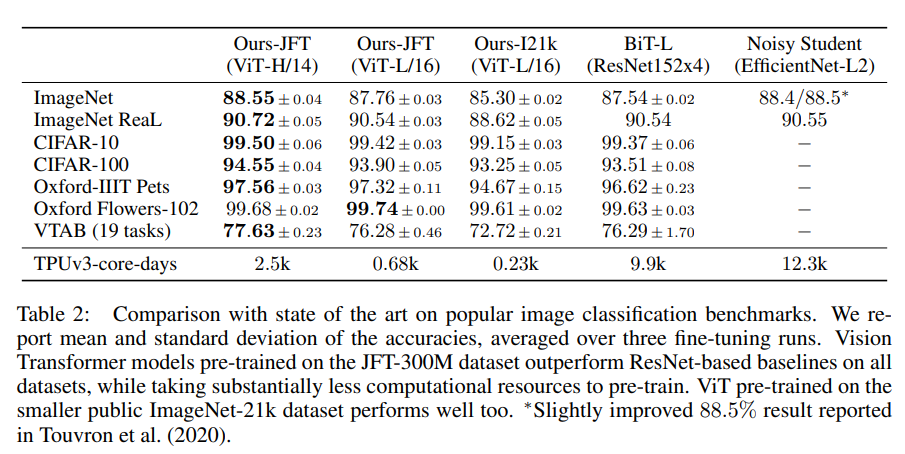
Table 2展示了在JFT上预训练的ViT与SOTA模型(BiT和Noisy Student)的对比
可以明显发现ViT-L/16已经在所有任务上打败了SOTA模型,而且更大的ViT-H/14甚至能有进一步提升
此外表中TPUv3-core-days表示TPUv3核心数与训练天数的乘积,可以发现ViT相较SOTA需要少很多的计算资源
Data Requirements
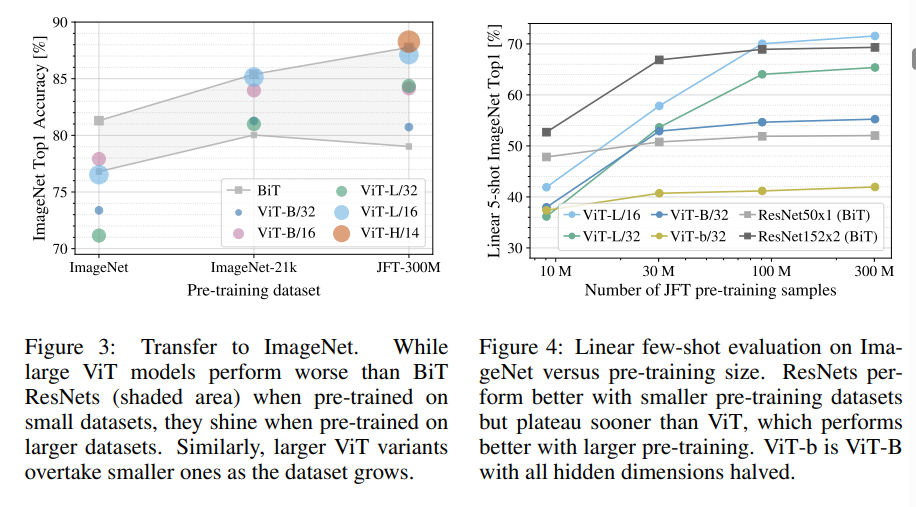
比较有趣的是,ViT在较小的数据集上表现不如SOTA,只有在大数据集上ViT才能展现出其实力
如fig3所示,数据集大小从ImageNet、ImageNet-21K到JFT-300M依次递增,可以看到在ImageNet上ViT表现都低于BiT,ViT-Large甚至低于ViT-Base,而在ImageNet-21K上,几个模型表现相近,在JFT上则ViT完胜
fig4是不同大小的JFT子集上进行预训练的结果,纵轴为 linear few-shot accuracy,从其中可得到同样结果
这些结果证实了一个直觉:CNN的归纳偏好对小数据集更有用,但对于大数据集,直接从数据中学习相关模式更有效
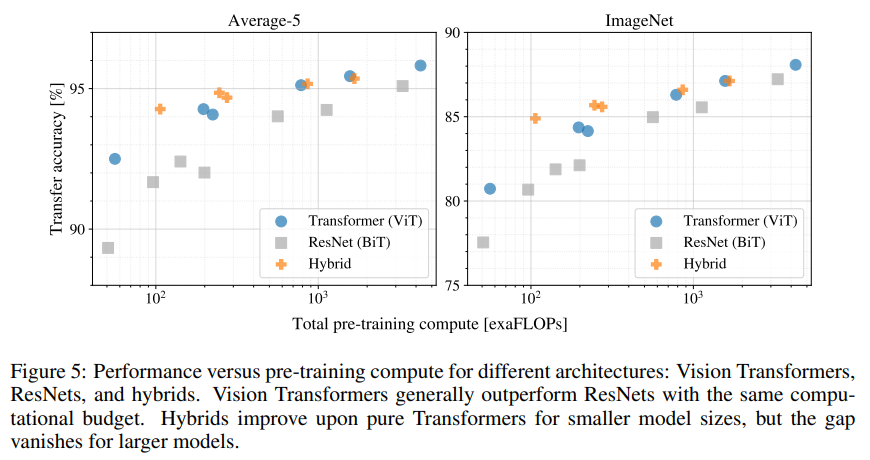
Scaling Study
fig5展示了对ViT模型缩放的研究
可以发现ViT使用了小2~4x计算成本就达到了与ResNet相近的迁移效果
此外混合模型在小计算量上略微超过了ViT,但在大模型上却还是ViT更优秀,而且ViT并没有随数据增大而饱和的迹象
Inspecting ViT
为理解ViT如何处理图像数据,论文还研究了ViT的内部图像表示
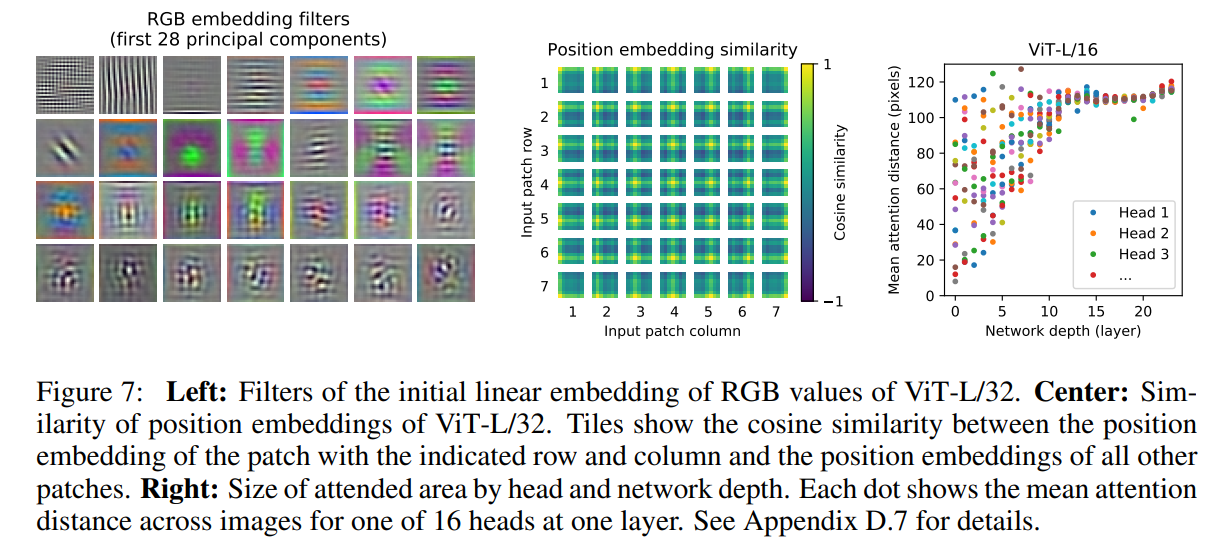
fig7左图展示的是patch embedding后的图像,论文这句结论不太会翻译
The components resemble plausible basis functions for a low-dimensional representation of the fine structure within each patch
fig7中间图展示的是patch embedding与position embedding相加的结果,其中可以很明显的看见2D位置信息,这也是为什么之前说2D position embedding并没有比1D好,因为1D已经学得了很好的表达
论文附录还展示了更大分辨率图像position embedding之后的特征图,其中还可以看到明显的正弦结构
通过一层的attention权重矩阵可以得到该层在整个图像空间上的平均attention距离,attention可以与CNN的感受野类比,fig7右图展示的就是不同深度的层与平均attention距离的关系
可以看到即使是低层,一些attention head也已经注意到了几乎整个图像
论文的fig6还将ViT在图像上attention到的部分做了可视化,可以明显看到attention部分都是与分类任务语义相关的区域
最后,论文还尝试了与BERT类似的无监督预训练,即masked path预测,但结果并不如有监督预训练