EfficientNet论文解读
论文链接:EfficientNet- Rethinking Model Scaling for Convolutional Neural Networks
Introduction
对CNN来说,增大模型规模被广泛地用以提高模型准确率,具体来说可以从3个维度进行:
- 增大深度depth,即增加层数
- 增大宽度width,即增加channel数
- 增大图像分辨率image resolution
先前的研究一般都只对其中一个维度进行缩放
虽然对三个维度同时进行任意缩放是可行的,但其需要繁复的手动调整,且往往不能获得更好的结果
因此该论文提出了一种复合缩放方法(compound scaling method)来对CNN进行缩放
Compound Model Scaling
CNN通常被划分为多个stage,每个stage的结构相同(例如ResNet),因此可以将CNN定义为
其中$\mathcal{F}{i}^{L{i}}$表示$\mathcal{F}{i}$在第$i$个stage重复$L{i}$次,$\langle H{i},W{i},C_{i}\rangle$表示stage i的输入特征图$X$的尺寸
常规的CNN设计大多关注$\mathcal{F}{i}$的设计,而模型缩放则不改变$\mathcal{F}{i}$,只尝试扩展网络深度$L_i$,宽度$C_i$和分辨率$(H_i,W_i)$
为进一步简化问题,我们限制所有层都以恒定的比率均匀缩放(all layers be scaled uniformly with constant ratio)
我们的目标是在给定的资源限制下最大化模型准确率,也即以下优化问题
其中$w,d,r$是分别是网络宽度、深度和分辨率的缩放系数,$\hat{\mathcal{F}_{i}},\hat{L_i},\hat{H_i},\hat{W_i},\hat{C_i}$则是预定义的baseline网络参数
Scaling Dimensions
由于$w,d,r$值相互影响,且受限于不同的资源,传统方法大多只对其中一个维度进行缩放
- 深度(d):
更深的网络能捕捉更丰富和复杂的特征,并在新任务上获得更好的泛化效果
虽然skip connection、batch normalization等技术解决了深度网络上的梯度消失问题
但是加深非常大深度的网络获得的准确率提升却越来越小,例如ResNet-1000与ResNet-101准确率非常接近
- 宽度(w):
增大模型宽度一般用于小型网络,更宽的网络倾向于扑捉到更多细粒度特征,且更容易训练
然而非常深但浅层的网络难以捕捉高层特征,经验结果表明更宽的网络准确率饱和很快
- 分辨率(r):
当输入图像分辨率更高时,CNN可以潜在地捕捉到更多细粒度的pattern
但是对于已经非常大的分辨率,增大分辨率获得的准确率提升很小
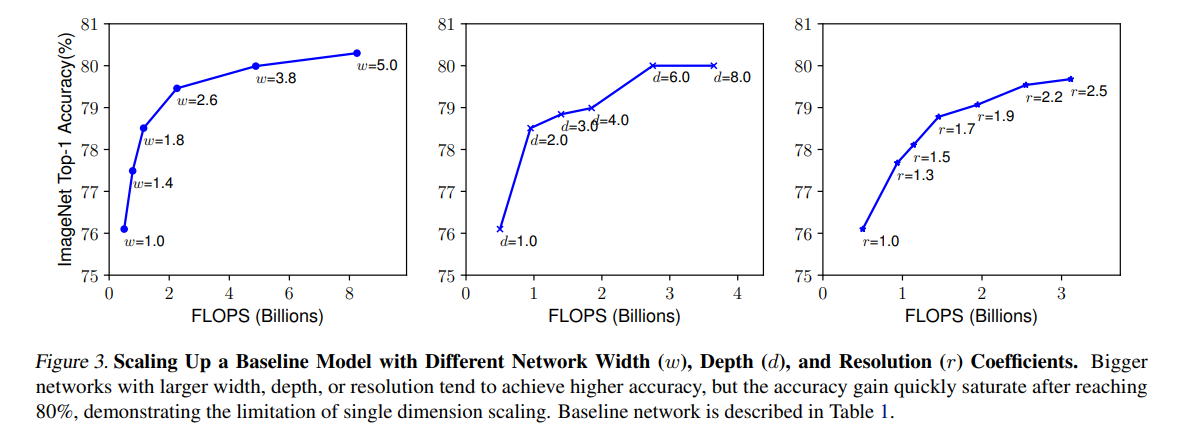
下图展示了对baseline模型分别增大$d,w,r$获得的FLOPS-accuracy曲线图,由此我们可以得到第一个观察结果
- Observation 1:增大网络深度、宽度、分辨率中的任一维度都会提升准确率,但更大的模型得到的准确率提升越来越少
Compound Scaling
经验结果表明,不同的缩放维度$w,d,r$不是独立的
直觉上,对于更高分辨率的图像,我们需要增大网络深度,通过更大的感受野来捕捉包含更多像素的相似特征,相应的还需要增大网络宽度,以便捕捉包含更多像素的细粒度pattern
这种经验和直觉表明,我们需要平衡不同维度的缩放尺寸,而不是仅仅缩放单一维度
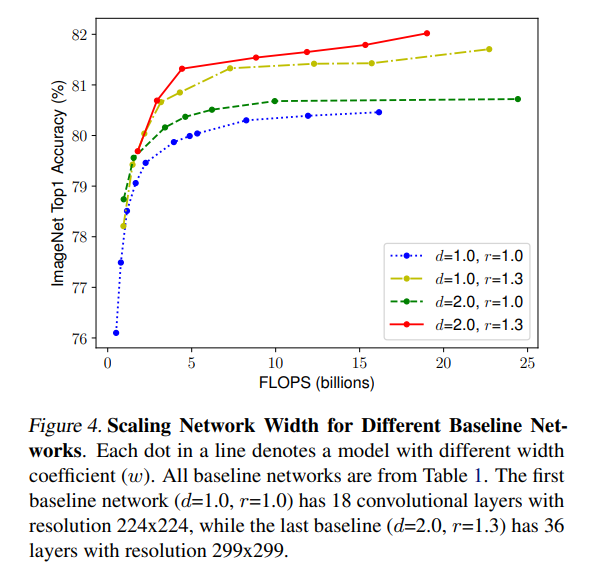
下图是对这种猜想的一个验证,可以发现同时增大w和r在相同FLOPS下获得了更大的准确率,由此我们可以得到第二个观察结果
- Observation 2:为了获得更高的准确率和效率,平衡CNN网络的宽度、深度和分辨率所有三个维度非常重要
针对Observation 1&2,论文提出了一种新的复合缩放方法(compound scaling method)
其中$\phi$是由用户指定的复合缩放因子,其控制了资源可用量
而$\alpha,\beta,\gamma$则表明如何分配多余的资源,其值可以通过一个小的网格搜索(grid search)来确定
因此利用上式缩放CNN将增加$(\alpha \cdot\beta^2\cdot\gamma^2)^{\phi}$的FLOPS消耗,也即增加 $2^{\phi}$
EfficientNet
由于compound scaling method不改变baseline模型的$\hat{\mathcal{F}_{i}}$,因此有一个好的baseline模型也十分重要
论文中使用了神经架构搜索(Neural Architecture Search, NAS)来建立baseline模型
具体的,NAS搜索空间与论文 MnasNet: Platform-aware neural architecture search for mobile 相同
优化目标为 $ACC(m)\times [FLOPS(m)/T]^w$,其中$ACC(m),FLOPS(m)$分别为模型$m$的准确率和FLOPS,$T$为目标FLOPS,$w=-0.07$为平衡准确率和FLOPS的超参数
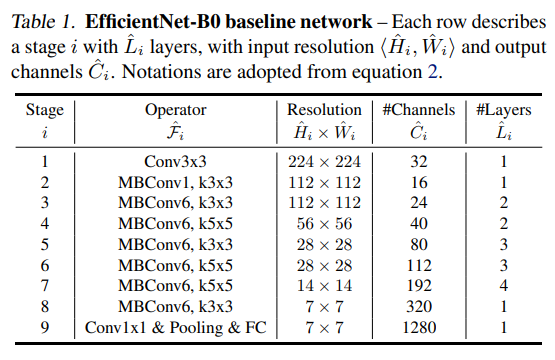
基于该方法得到的baseline模型称为EfficientNet-B0,其结构如图所示
接下来将compound scaling method应用于EfficientNet-B0,分为两步
- 固定$\phi=1$,即假设有两倍的可用资源,对$\alpha,\beta,\gamma$应用网格搜索,得到最优值为$\alpha=1.2,\beta=1.1,\gamma=1.15$
- 固定$\alpha,\beta,\gamma$,使用不同的$\phi$对模型进行缩放,得到EfficientNet-B1~B7
Experiment
论文中的结果图表很多,这里仅展示部分有代表性的图表
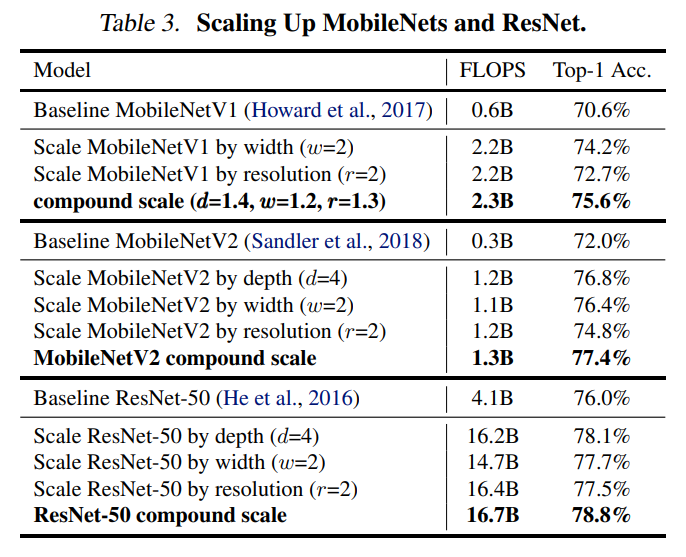
首先是将ResNet和MobileNet作为baseline模型使用compound scaling method
可以看到相比单一维度的缩放,复合缩放确实对几个模型都提高了准确率
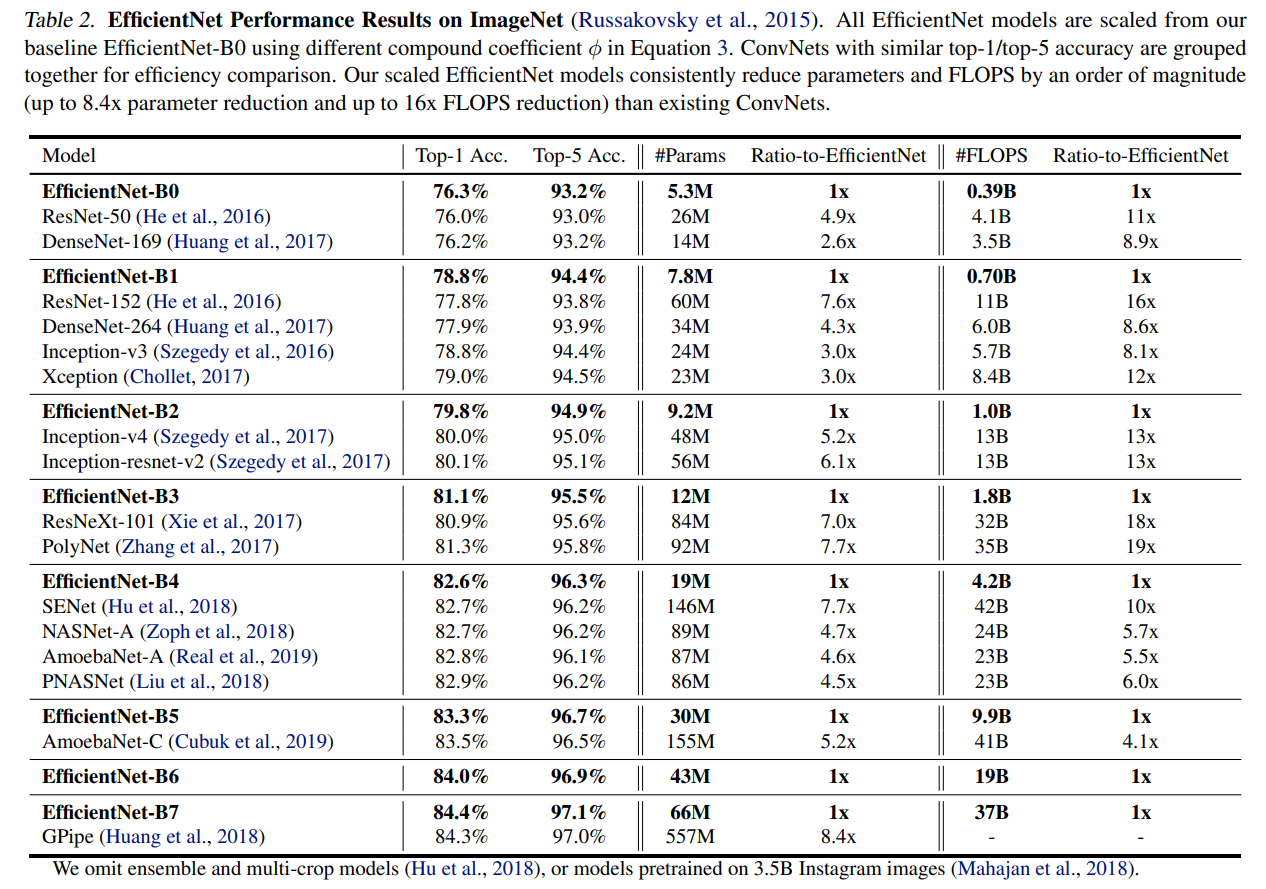
然后是对EfficientNet-B0进行缩放,可以发现在准确率相似的情况下,EfficientNet有小得多的参数量和FLOPS
例如EfficientNet-B7,准确率比GPipe更高但参数量少了近8.4倍
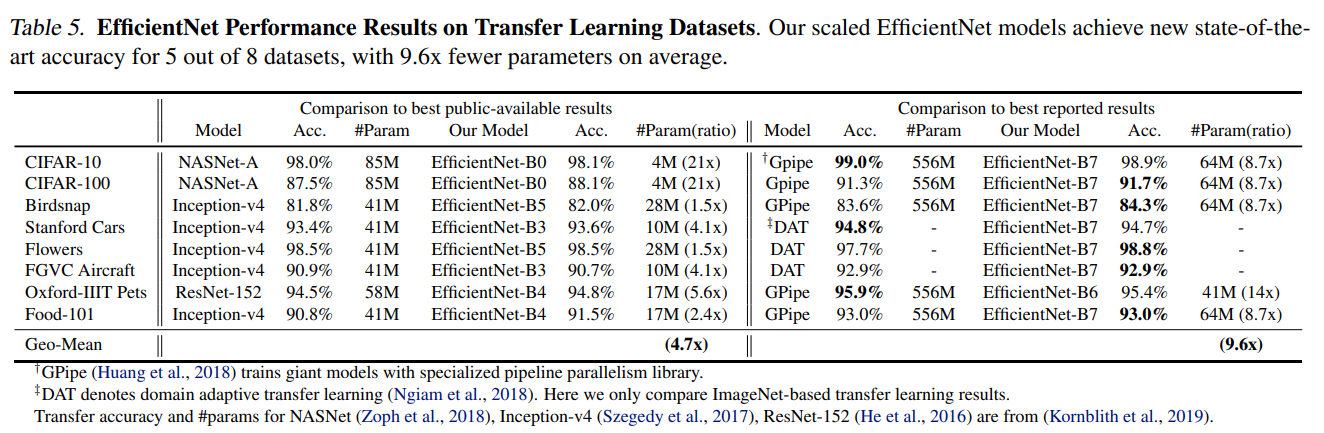
论文还比较了EfficientNet的迁移学习能力,如图所示