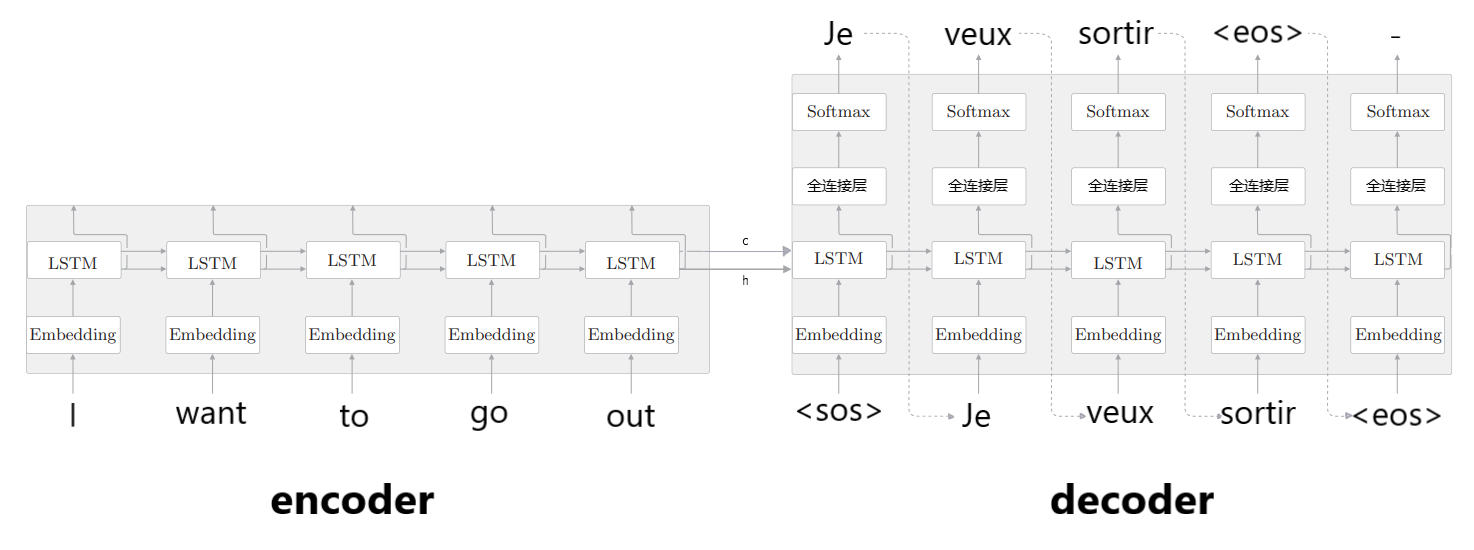
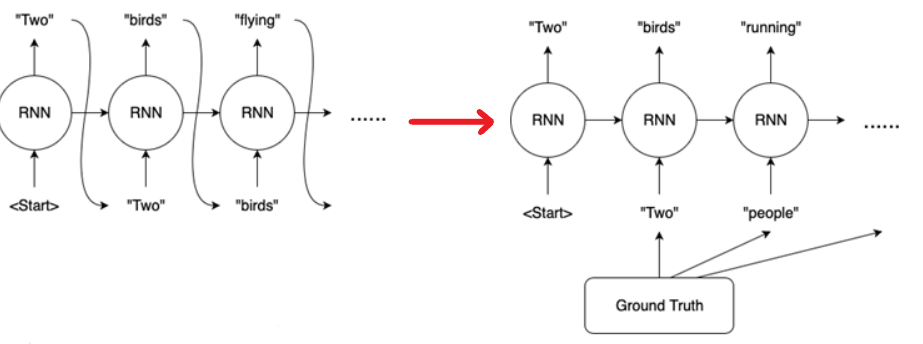
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
| """ Seq2Seq
paper: Sequence to Sequence Learning with Neural Networks
see: https://proceedings.neurips.cc/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf
"""
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense, Embedding, TimeDistributed
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import random
class TatoebaPreprocessor:
"""
Load and preprocess the English-French sentence pair dataset.
The dataset consists of tab-delimited bilingual sentence pairs.
The sentence pairs are selected from the Tatoeba Project by http://www.manythings.org/.
see: http://www.manythings.org/anki/fra-eng.zip
finding datasets of more languages: http://www.manythings.org/anki/
"""
def __init__(self, dataDir, num_samples=None, shuffle=True):
self.text_en, self.text_fra = self.readData(dataDir, num_samples, shuffle)
self.seq_en, self.dict_en = self.buildVocab(self.text_en)
self.seq_fra, self.dict_fra = self.buildVocab(self.text_fra)
self.dict_en['<unknown>'] = 0
self.dict_fra['<unknown>'] = 0
def getOriginalText(self):
""" 获取原文本数据 """
return self.text_en, self.text_fra
def getVocab(self):
""" 获取 id->word字典 和 word->id字典 """
dict_en_rev = dict((id, char) for char, id in self.dict_en.items())
dict_fra_rev = dict((id, char) for char, id in self.dict_fra.items())
return (self.dict_en, dict_en_rev), (self.dict_fra, dict_fra_rev)
def getNumberOfWord(self):
""" 获取分词后不同单词数 """
num_word_en = len(self.dict_en.keys())
num_word_fra = len(self.dict_fra.keys())
return num_word_en, num_word_fra
def getPaddedSeq(self):
""" 填充索引化后的句子至相同长度 """
padded_seq_en = pad_sequences(self.seq_en, padding='post')
padded_seq_fra = pad_sequences(self.seq_fra, padding='post')
return padded_seq_en, padded_seq_fra
def buildVocab(self, text):
""" 分词并建立词汇表 """
tokenizer = Tokenizer(filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~')
tokenizer.fit_on_texts(text)
seq = tokenizer.texts_to_sequences(text)
return seq, tokenizer.word_index
def readData(self, dataDir, num_samples, shuffle):
""" 读取数据 """
with open(dataDir, 'r', encoding='utf-8') as f:
lines = f.readlines()
if num_samples:
lines = lines[:min(num_samples, len(lines))]
if shuffle:
random.shuffle(lines)
text_en = [line.split('\t')[0] for line in lines]
text_fra = ['\t ' + line.split('\t')[1] + ' \n' for line in lines]
return text_en, text_fra
class Seq2Seq:
def __init__(self):
preprocessor = TatoebaPreprocessor(dataDir='D:\\wallpaper\\datas\\fra-eng\\fra.txt')
self.text_en, self.text_fra = preprocessor.getOriginalText()
(self.dict_en, self.dict_en_rev), (self.dict_fra, self.dict_fra_rev) = preprocessor.getVocab()
num_word_en, num_word_fra = preprocessor.getNumberOfWord()
self.tensor_input, self.tensor_output = preprocessor.getPaddedSeq()
self.encoder, self.decoder, self.model = self.buildNet(num_word_en, num_word_fra, 256)
def buildEncoder(self, num_word, latent_dim):
inputs = Input(shape=(None,))
embedded = Embedding(num_word, 128)(inputs)
_, state_h, state_c = LSTM(latent_dim, return_state=True)(embedded)
return Model(inputs, [state_h, state_c])
def buildDecoder(self, num_word, latent_dim):
inputs = Input(shape=(None,))
embedded = Embedding(num_word, 128)(inputs)
input_state_h = Input(shape=(latent_dim,))
input_state_c = Input(shape=(latent_dim,))
lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
outputs, output_state_h, output_state_c = lstm(
embedded, initial_state=[input_state_h, input_state_c]
)
prob = TimeDistributed(Dense(num_word, activation='softmax'))(outputs)
return Model(
[inputs, input_state_h, input_state_c],
[prob, output_state_h, output_state_c]
)
def buildNet(self, num_word_in, num_word_out, latent_dim):
encoder = self.buildEncoder(num_word_in, latent_dim)
decoder = self.buildDecoder(num_word_out, latent_dim)
inputs_encoder = Input(shape=(None,))
inputs_decoder = Input(shape=(None,))
states = encoder(inputs_encoder)
prob, _, _ = decoder([inputs_decoder] + states)
model = Model([inputs_encoder, inputs_decoder], prob)
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return encoder, decoder, model
def trainModel(self, epochs, batch_size):
outputs_shift = np.zeros(self.tensor_output.shape)
outputs_shift[:, :-1] = self.tensor_output.copy()[:, 1:]
self.model.fit(
[self.tensor_input, self.tensor_output], outputs_shift,
epochs=epochs, batch_size=batch_size, validation_split=0.2,
)
self.test()
def test(self):
for idx in range(5):
input_seq = self.tensor_input[idx: idx + 1]
translated = self.translate(input_seq)
print('-')
print('Input sentence:', self.text_en[idx])
print('Decoded sentence:', translated)
print('Ground truth:', self.text_fra[idx])
def translate(self, input_seq):
states = self.encoder.predict(input_seq)
cur_word = np.zeros((1, 1))
cur_word[0, 0] = self.dict_fra['\t']
max_length = 80
translated = ''
for _ in range(max_length):
outputs, state_h, state_c = self.decoder.predict([cur_word] + states)
output_idx = np.argmax(outputs[0, -1, :])
output_word = self.dict_fra_rev[output_idx]
if output_word == '\n':
break
translated += ' ' + output_word
cur_word = np.zeros((1, 1))
cur_word[0, 0] = output_idx
states = [state_h, state_c]
return translated
seq2seq = Seq2Seq()
seq2seq.trainModel(epochs=4, batch_size=32)
|