论文链接:Deep Residual Learning for Image Recognition
残差网络的由来
随着神经网络研究的深入,人们发现了深度的增加会为模型带来巨大的能力提升
但是网络深度的增加也带来了梯度消失/爆炸的问题
幸运的是这一问题被初始归一化和归一化层解决了,它们使得网络得以收敛
然而,解决了梯度消失问题的深度网络却又暴露出了退化问题
即网络加深到一定程度后,继续加深网络反而会使训练误差增大
不幸的是研究表明这个问题并不是过拟合引起的
可退化问题实际上并不应该发生
我们考虑一个已有的层数较少的模型和按其相同结构加深的模型
假如深度模型中新加入的层都表示恒等映射,那么两个模型至少应该有相同性能
Kaiming He认为这种退化问题是目标隐函数难以用现有optimizer近似导致的
所以他提出了残差结构来解决这一问题
残差结构
残差结构如图所示
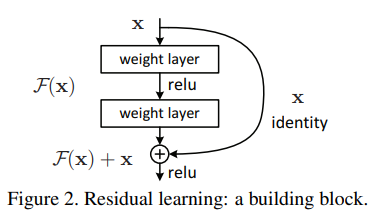
假设网络中一部分堆叠层的目标隐函数为$H(x)$
在残差结构中这部分对叠层的目标则为$F(x)=H(x)-x$
而输入x被直接以恒等形式(identity shortcut)连接至输出,即残差结构的输出为$F(x)+x$
基于前面的假设,当恒等映射确实为深度网络中某些层的最优选择时
残差结构中的层就只需要简单的将权值置0
即使实际上目标函数并不是恒等映射,也可以发现残差结构能使得网络更有效地收敛
同时很重要的一点是,残差结构并没有引入多余的参数
残差网络
He在论文中给出了多个不同深度的resnet模型
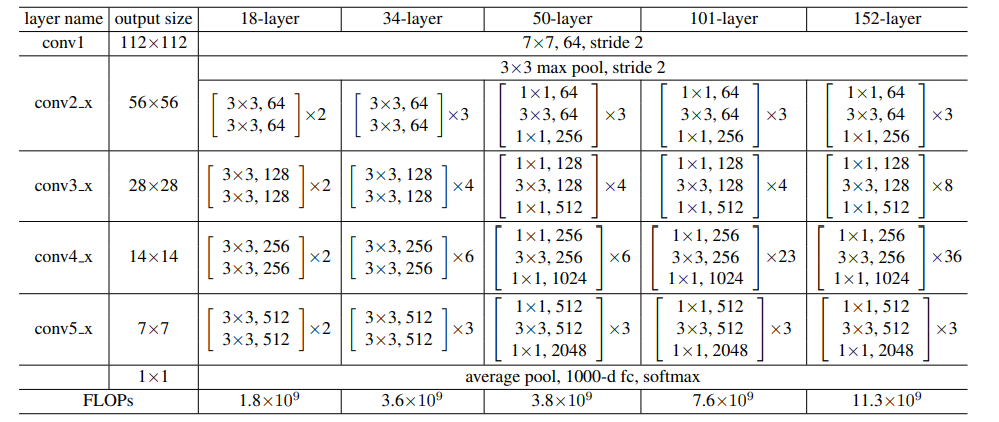
还有34-layer resnet的图解

需要注意的是,对于恒等跳跃连接对应的输入和输出维度不同的情况,作者给出了两种方案
- 用0填充来增加维度
- 将恒等跳跃连接变为一个单独的层(例如一个1x1卷积)
作者的实验表明两种方法效果相似,但前者不引入参数,计算效率更高
此外一个residual block不应该只有一层
否则它会变成$\boldsymbol{y}=\boldsymbol{W}\boldsymbol{x}+\boldsymbol{x}$,使得残差结构毫无意义
Keras代码实现
为了方便代码实现,维度变化的shortcut用了1x1的卷积
论文所述的zero-padding在keras中不太好实现,实际上keras官方文档中的实例也用了卷积
zero-padding shortcut的实现可参考github讨论Zero-padding for ResNet shortcut connections when channel number increase
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| from keras.models import Model, Sequential
from keras.layers import Dense, Conv2D, Input, Activation, BatchNormalization, \
MaxPool2D, GlobalAveragePooling2D, Add
from keras.optimizers import Adam
class ResNet:
def __init__(self):
self.input_shape = (224, 224, 3)
self.resnet = self.buildNet()
self.resnet.compile(optimizer=Adam(1e-4), loss='categorical_crossentropy')
print(self.resnet.summary())
def buildNet(self):
inputs = Input(self.input_shape)
x = Conv2D(64, kernel_size=7, strides=2, padding='same')(inputs)
x = MaxPool2D(pool_size=(3, 3), strides=2)(x)
num_block = [3, 4, 6, 3]
for k in range(4):
for idx in range(num_block[k]):
downsample = (idx==0 and k!=0)
x = self.resblock(inputs=x, filters=64*2**k, downsample=downsample)
x = GlobalAveragePooling2D()(x)
outputs = Dense(1000, activation='softmax')(x)
return Model(inputs, outputs)
def resblock(self, inputs, filters, downsample=False):
strides = 2 if downsample else 1
x = Conv2D(filters, kernel_size=3, strides=strides, padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
if downsample:
inputs = Conv2D(filters, kernel_size=1, strides=2, padding='same', activation='relu')(inputs)
x = Add()([inputs, x])
outputs = Activation('relu')(x)
return outputs
if __name__ == '__main__':
resnet = ResNet()
|
Pytorch代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| import torch
import torch.nn as nn
import torchvision
import numpy as np
class ResBlock(nn.Module):
def __init__(self, input_channel, filters, downsample=False):
super().__init__()
self.downsample = downsample
stride = 2 if downsample else 1
self.layer1 = nn.Sequential(
nn.Conv2d(input_channel, filters, kernel_size=3, stride=stride, padding=1),
nn.ReLU(),
nn.BatchNorm2d(filters)
)
self.layer2 = nn.Sequential(
nn.Conv2d(filters, filters, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(filters)
)
if downsample:
self.shortcut = nn.Sequential(
nn.Conv2d(input_channel, filters, kernel_size=1, stride=2, padding=0),
nn.ReLU(),
)
def forward(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
if self.downsample:
inputs = self.shortcut(inputs)
outputs = torch.add(inputs, x)
return outputs
class ResNet(nn.Module):
def __init__(self):
super().__init__()
self.input_channel = 3
self.buildNet()
def buildNet(self):
def buildBlock(num, input_channel, filters, downsample=True):
layer = []
for idx in range(num):
downsample = (idx == 0 and downsample)
input_channel = filters if idx !=0 else input_channel
layer.append(ResBlock(input_channel=input_channel, filters=filters, downsample=downsample))
return nn.Sequential(*layer)
self.conv1 = nn.Conv2d(self.input_channel, 64, kernel_size=7, stride=2, padding=3)
self.maxpool = nn.MaxPool2d(3, stride=2)
num_block = [3, 4, 6, 3]
self.conv2 = buildBlock(num_block[0], input_channel=64, filters=64, downsample=False)
self.conv3 = buildBlock(num_block[1], input_channel=64, filters=128)
self.conv4 = buildBlock(num_block[2], input_channel=128, filters=256)
self.conv5 = buildBlock(num_block[3], input_channel=256, filters=512)
self.global_avgpool = nn.AdaptiveAvgPool2d((1,1))
self.classifier = nn.Linear(512, 10)
def forward(self, inputs):
x = self.conv1(inputs)
x = self.maxpool(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.global_avgpool(x)
x = x.view(x.size(0), -1)
outputs = self.classifier(x)
return outputs
|
