
应用Attention机制的Seq2Seq
论文链接:Neural Machine Translation By Jointly Learning To Align And Translate
什么是Attention
Seq2Seq解读与实现中讲解的原始的Seq2Seq模型中存在一个问题
即encoder的输出是固定长度的向量
如果输入序列很长,这个定长向量就很可能无法浓缩所有信息
首先很容易想到将encoder每个timestep的输出都保留下来
这样就有了一个尺寸为(timestep, output_dim)的矩阵表示encoder的处理结果(原来seq2seq相当于只保留了这个矩阵最后一行)
那么要如何处理这个矩阵并传递给decoder呢
考虑到人类的翻译过程,我们首先会进行 “我=I” “咖啡=coffee” 这样一个单词对应关系的转化
这个过程称为对齐(alignment)
也就是说人类会专注于一个单词(或短语)进行翻译
我们把这种过程应用于神经网络,就叫Attention机制
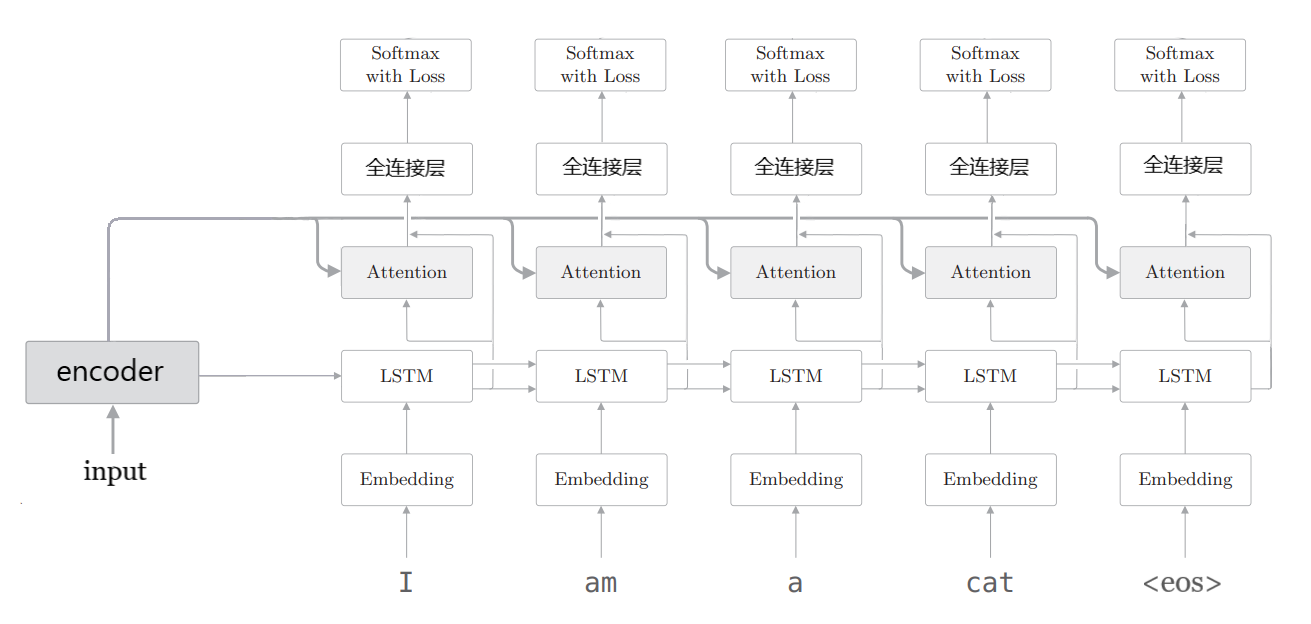
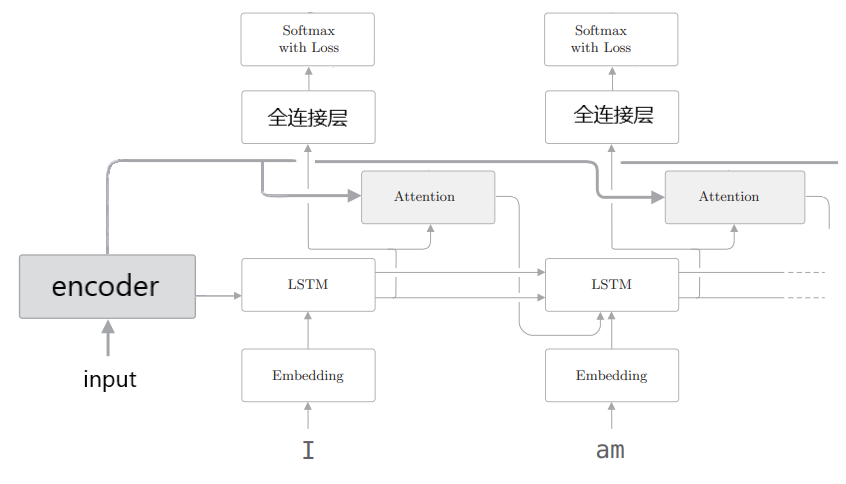
加入Attention机制的seq2seq如图所示
encoder最后一个cell的状态仍然作为decoder的初始状态
不同之处加入了Attention层,用于从encoder所有timestep的输出中选出decoder当前timestep要专注的部分
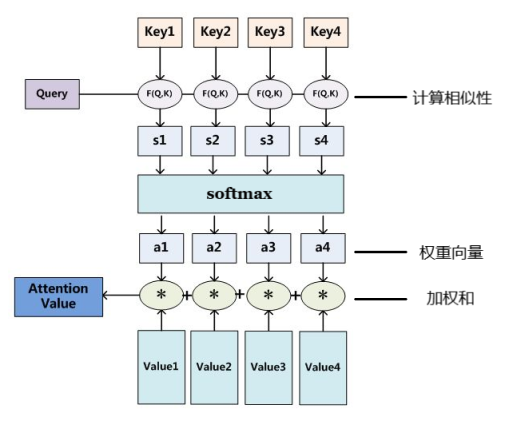
Attention层的内部原理
记encoder、decoder输出张量分别为$V,Q$,并设$V,Q$ 尺寸分别为 $(T_V,dim)$ 和 $(T_Q,dim)$
其中$T_V,T_Q$分别为encoder、decoder的时间步数量(也即句子最大长度)
理论上$V$(或$Q$)的第$t$行向量主要包含了encoder(或decoder)对输入中第$t$个单词的处理结果
依照前述的对齐思想,对于$Q$的第$i$行,我们想找到它在$V$中最应该专注的一行$j$,并用这两行向量合并处理
然而实际中选择确定的一行并不可行,因为“选择”不是可微分的
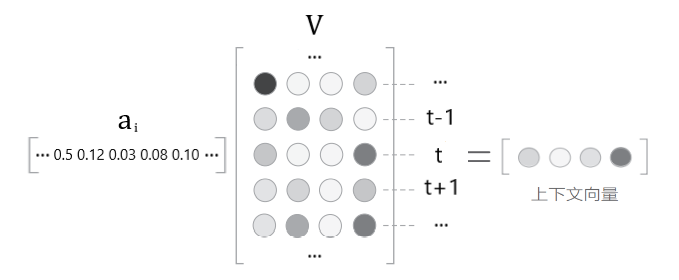
因此对于$Q$的第$i$ 行,我们改为给$V$的每一行赋予一个权值,表示对该行的专注度
也即,用一个尺寸为$(1, T_V)$权重向量$a_i$与$V$作矩阵乘法
就得到了一个用加权和表示对 $V$ 各行专注度的上下文向量
显然,要计算$Q$每行对$V$的上下文向量,就需要一个尺寸为$(T_Q,T_V)$的权重矩阵
下面再来考虑权重矩阵如何获得
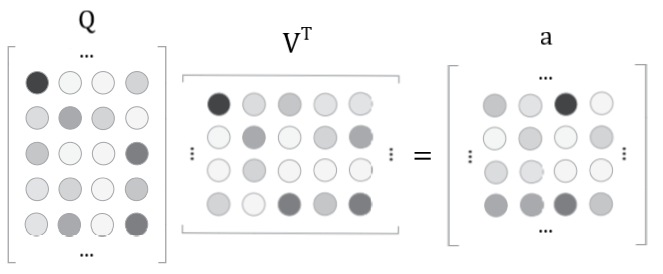
对于$Q$的第$i$行,权重向量$ai$实质上是表示**向量$Q{i,}$与$V$各行向量的相似度**
表示两个向量相似程度的方法有很多,最简单的就是内积
因此,只要矩阵$QV^T$就是我们要的权重矩阵$a$ ,其第$i$行对应$Q_{i,}$的权重向量$a_i$
当然还需要对每个行向量$a_i$进行softmax激活来正规化数值
综上整个Attention层的结构如下图所示
更一般的描述Attention
考虑Attention思想更一般的抽象化描述
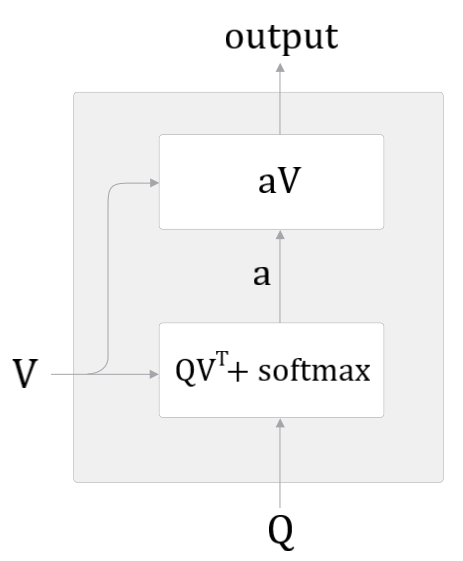
我们已知(Key, Value)张量对以及目标张量Query(分别记为$K,V,Q$)
首先计算$Q$中特定的一行与$K$每一行的相似度,若用点积表示相似度,则相似度矩阵为$QK^T$
对$QK^T$每一行分别softmax正规化得到权重矩阵$a$,表示$Q$中特定的一行对$K$每一行的专注度
那么Attention的输出就是$aV$,表示用加权和描述$Q$对$V$各行给与不同关注度得到的结果
综上,Attention的数学表达即为
其中输入张量$Q,K,V$的尺寸分别为$(samples,T_Q,dim)$,$(samples,T_K,dim)$,$(samples,T_K,dim)$,输出张量尺寸为$(samples, T_Q, dim)$
实际中Key和Value往往是相同的,上述Seq2Seq就是如此
Attention的应用方式
前面第一节的图示中是将Attention输出与RNN输出直接进行concatenate再输入全连接层
很多文献中还使用如下图所示的方法利用attention输出
即每个RNN cell的输出计算Attention后,再将Attention结果输入下一个RNN cell
实际中两种方法表现都很优异
Keras实现带Attention的Seq2Seq
代码中用了English to French sentence pairs数据集,数据预处理见Seq2Seq解读与实现
代码中使用了keras已实现的Attention层,且encoder部分按照论文使用了双向RNN
1 | """ Seq2Seq with Attention |