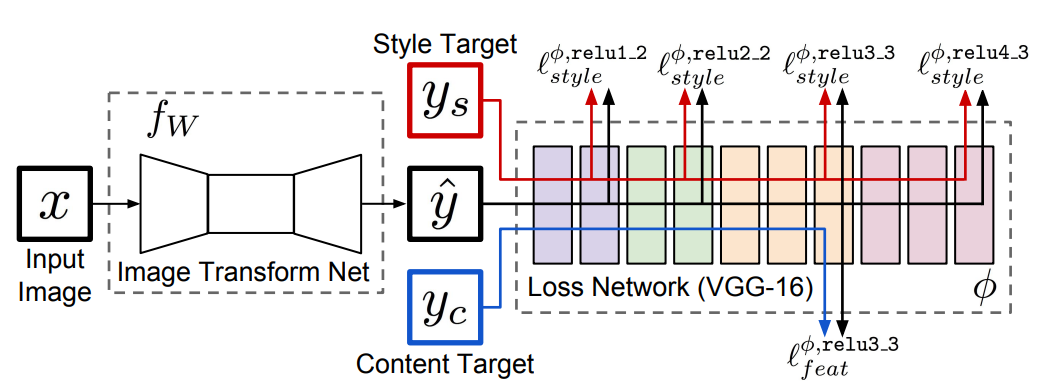
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
| """ Neural Style Transfer using Perceptual Loss
paper: Perceptual Losses for Real-Time Style Transfer and Super-Resolution
see: https://link.springer.com/chapter/10.1007/978-3-319-46475-6_43
"""
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, Conv2DTranspose, BatchNormalization, Activation, Add
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import vgg16
import tensorflow.keras.backend as K
import numpy as np
import cv2
import glob
import random
def resblock(inputs, filters):
x = Conv2D(filters, kernel_size=3, strides=1, padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Add()([inputs, x])
outputs = Activation('relu')(x)
return outputs
def buildTransformationNet():
inputs = Input(shape=(None, None, 3))
x = Conv2D(128, kernel_size=9, strides=2, padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(256, kernel_size=3, strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
for _ in range(3):
x = resblock(x, 256)
x = Conv2DTranspose(128, kernel_size=3, strides=2, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2DTranspose(64, kernel_size=3, strides=2, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
outputs = Conv2D(3, kernel_size=9, strides=1, padding='same', activation='tanh')(x)
return Model(inputs, outputs)
def buildLossNet():
vgg = vgg16.VGG16(include_top=False, weights='imagenet')
outputs_dict = dict([(layer.name, layer.output) for layer in vgg.layers])
return Model(vgg.inputs, outputs_dict)
def gram_matrix(x):
shape = K.cast(K.shape(x), 'float32')
x = K.permute_dimensions(x, (0, 3, 1, 2))
x = K.reshape(x, (K.shape(x)[0], K.shape(x)[1], -1))
gram = tf.matmul(x, K.permute_dimensions(x, (0, 2, 1))) / K.prod(shape[1:])
return gram
def style_loss(style, combination, reduction='mean'):
gram_style = gram_matrix(style)
gram_combination = gram_matrix(combination)
square = K.sum(K.square(gram_style - gram_combination), axis=[1, 2])
if reduction == 'mean':
return K.mean(square)
else:
return K.sum(square)
def content_loss(content, combination, reduction='mean'):
square = K.sum(K.square(content - combination), axis=[1, 2, 3])
if reduction == 'mean':
return K.mean(square)
else:
return K.sum(square)
def tv_loss(img, reduction='mean'):
t = tf.image.total_variation(img)
if reduction == 'mean':
return K.mean(t)
else:
return K.sum(t)
def perceptualLoss(img_content, img_style, img_combination, loss_net):
content_weight = 2e-6
style_weight = 3e-2
tv_weight = 1e-5
content_layer_name = 'block4_conv3'
style_layer_names = [
"block1_conv2",
"block2_conv2",
"block3_conv2",
"block4_conv2",
"block5_conv2"
]
loss = K.variable(0.)
feat_content = loss_net(img_content)
feat_style = loss_net(img_style)
feat_combin = loss_net(img_combination)
loss = loss + content_weight * content_loss(
feat_content[content_layer_name], feat_combin[content_layer_name])
for layer_name in style_layer_names:
sloss = style_loss(feat_style[layer_name], feat_combin[layer_name])
loss = loss + style_weight / len(style_layer_names) * sloss
loss += tv_weight * tv_loss(img_combination)
return loss
class DataLoader:
def __init__(self, dir_content_img, fpath_style_img, batch_size, img_shape):
self.batch_size = batch_size
self.img_shape = img_shape
self.idx_cur = 0
self.flist = glob.glob(dir_content_img + '/*.jpg')
self.fnum = len(self.flist)
self.img_style = self.processImage(fpath_style_img)
def processImage(self, fpath):
img = cv2.imread(fpath, 1)
img = cv2.resize(img, (self.img_shape[1], self.img_shape[0]))
img = img.astype(np.float32) / 127.5 - 1
return img
def getNumberOfBatch(self):
return (self.fnum // self.batch_size) + (self.fnum % self.batch_size != 0)
def reset(self):
self.idx_cur = 0
random.shuffle(self.flist)
def __iter__(self):
return self
def __next__(self):
if self.idx_cur >= self.fnum:
self.reset()
raise StopIteration
if self.idx_cur + self.batch_size - 1 < self.fnum:
length = self.batch_size
else:
length = self.fnum - self.idx_cur
img_style = np.tile(self.img_style, (length, 1, 1, 1))
img_content = np.zeros((length, *self.img_shape))
for k in range(length):
img_content[k] = self.processImage(self.flist[self.idx_cur+k])
self.idx_cur += length
return img_content, img_style
def train(transformation_net, loss_net, epochs, batch_size=8):
optimizer = Adam()
dataLoader = DataLoader(
dir_content_img=r'../input/image-colorization/unlabeled2017_subsample',
fpath_style_img=r'../input/styletransfer/style.jpg',
batch_size=batch_size, img_shape=(256, 256, 3)
)
num_batch = dataLoader.getNumberOfBatch()
for epoch in range(1, epochs + 1):
for step, (img_content, img_style) in enumerate(dataLoader):
with tf.GradientTape() as tape:
img_combination = transformation_net(img_content)
loss = perceptualLoss(img_content, img_style, img_combination, loss_net)
grads = tape.gradient(loss, transformation_net.trainable_weights)
optimizer.apply_gradients(zip(grads, transformation_net.trainable_weights))
print("epoch {}/{}, step {}/{}: loss={:.4f}".format(
epoch, epochs, step+1, num_batch, loss))
if (step+1) % 400 == 0:
img = img_combination.numpy()[0]
img = (img + 1) * 127.5
cv2.imwrite('./epoch{}step{}.png'.format(epoch, step+1), img.astype(np.uint8))
transformation_net = buildTransformationNet()
loss_net = buildLossNet()
train(transformation_net, loss_net, epochs=10)
|