什么是神经风格迁移 图像风格迁移一直是cv领域的一个难题非参数化 算法,这些算法的局限都在于只能提取图像的低层特征
2015年Gatys等人提出了基于神经网络的图像风格迁移算法,即神经风格迁移预训练的深度CNN 提取图像高层特征 ,独立 构造出了图像的内容/风格表示
论文链接:
A neural algorithm of artistic style
Image Style Transfer Using Convolutional Neural Networks
自己训练的模型效果如下
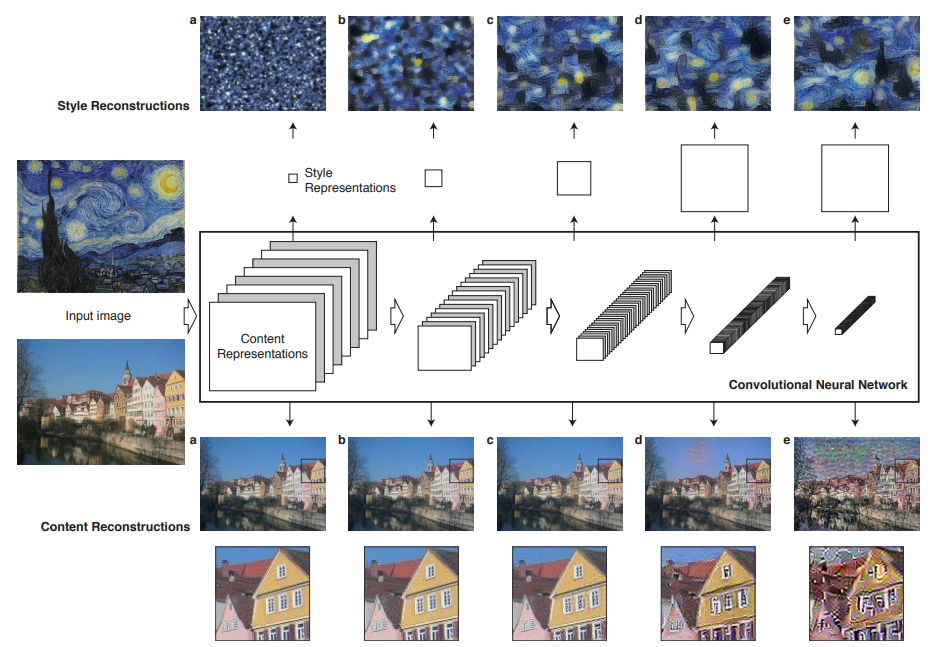
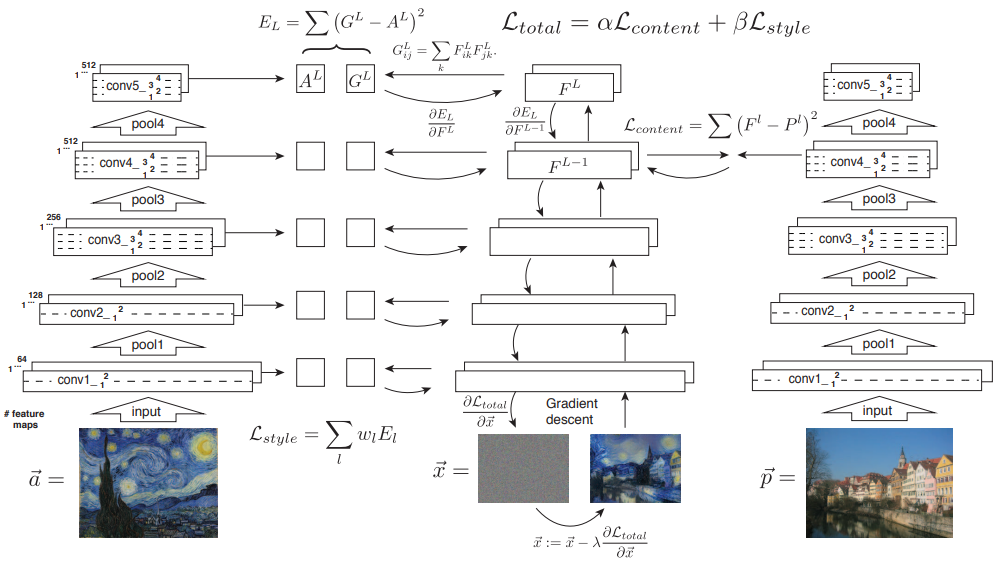
内容与风格的提取 深度内容表达 以VGG为例,为了将深度CNN模型每一层学得的特征可视化随机噪声图 和一张正常照片同时输入网络,计算网络第l层输出的两张特征图之间的loss,再对噪声图进行梯度下降
即设$\vec{p},\vec{x}$分别为输入的原图和噪声图,$P^l,F^l$分别为他们在网络第$l$层的输出特征图,其尺寸为$(H_l,W_l,C_l)$,则有square-error
对$F^l$求导有
之后即可通过反向传播对$\vec{x}$进行梯度下降
使用该方法对VGG不同层学得的特征可视化的结果如图中下侧 所示
从图中可知网络越高层 学得的表达对图像内容(content) 越敏感,即捕获了输入图像中的物体以及它们的布局等,而并不限制每个像素的色值
因此我们将CNN网络高层的输出特征图 称为图像的内容表达(content representation)
深度风格表达 与内容表达不同,图像的风格表达通过计算网络不同层的特征图以及特征图不同通道的相关性 得到,而这种相关性通过gram矩阵 获得
设网络第$l$层输出的特征图尺寸为$(H_l,W_l,C_l)$,则gram矩阵$G^l\in \mathbb{R}^{C_l\times C_l}$,计算公式为
也即$G^l_{i,j}$为特征图通道$i$和通道$j$的内积
实际中操作中可以先将$F^l$转置,将通道维度提前,再将后两维展平,使其尺寸为$(C_l,H_lW_l)$,记为$F^{l’}$,则$G^l=F^{l’}F^{l’^{T}}$
同样通过对噪声图进行梯度下降 可以将VGG每层学得的风格表达可视化
即设$\vec{a},\vec{x}$分别为输入的原图和噪声图,$A^l,G^l$分别为他们在网络第$l$层的gram矩阵,则有mean-squared损失
由于风格损失还应考虑不同层的输出特征图的相关性,所以最终风格损失为
其中$w_l$为对应第$l$层风格损失的权重
包含不同层的风格损失的可视化结果如上图中上侧 所示,从左至右依次包含 (a)conv1_1 (b)conv1_1 conv2_1 (c)conv1_1 conv2_1 conv3_1 (d) conv1_1 conv2_1 conv3_1 conv4_1
可以发现包含的不同层次越多,风格损失的效果就更好
实现风格迁移 根据上述理论,可以通过同时最小化定义在某一层上的内容损失和定义在多层上的风格损失 ,并对一张噪声图进行梯度下降 实现神经风格迁移
以下为代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 """ Neural Style Transfer paper: A neural algorithm of artistic style see: https://arxiv.org/pdf/1508.06576.pdf paper: Image Style Transfer Using Convolutional Neural Networks see: https://openaccess.thecvf.com/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf Implementation reference: https://keras.io/examples/generative/neural_style_transfer/ """ import tensorflow as tffrom tensorflow.keras.models import Modelfrom tensorflow.keras.optimizers import RMSpropfrom tensorflow.keras.applications import vgg19import tensorflow.keras.backend as Kimport numpy as npimport cv2def gram_matrix (x ): x = K.permute_dimensions(x, (2 , 0 , 1 )) x = K.reshape(x, (K.shape(x)[0 ], -1 )) gram = K.dot(x, K.transpose(x)) return gram def style_loss (style, combination ): gram_style = gram_matrix(style) gram_combination = gram_matrix(combination) h, w, c = style.get_shape().as_list() fac = 4.0 * ((h * w) ** 2 ) * (c ** 2 ) return K.sum (K.square(gram_style - gram_combination)) / fac def content_loss (content, combination ): return K.sum (K.square(content - combination)) / 2.0 def calc_loss (outputs ): content_weight = 2e-4 style_weight = 1 content_layer_name = 'block5_conv2' style_layer_names = [ "block1_conv1" , "block2_conv1" , "block3_conv1" , "block4_conv1" , "block5_conv1" , ] loss = K.variable(0. ) features = outputs[content_layer_name] loss = loss + content_weight * content_loss(features[0 , :, :, :], features[2 , :, :, :]) for layer_name in style_layer_names: features = outputs[layer_name] sloss = style_loss(features[1 , :, :, :], features[2 , :, :, :]) loss = loss + style_weight / len (style_layer_names) * sloss return loss def preprocessImage (fpath, shape ): img = cv2.imread(fpath, 1 ) img = cv2.resize(img, shape) img = np.expand_dims(img, axis=0 ).astype(np.float32) img = img / 127.5 - 1 return img def saveImage (img, fpath ): img = (img + 1 ) * 127.5 img = np.clip(img, 0 , 255 ).astype("uint8" ) cv2.imwrite(fpath, img) def getFeatureExtractor (): vgg = vgg19.VGG19(include_top=False , weights='imagenet' ) outputs_dict = dict ([(layer.name, layer.output) for layer in vgg.layers]) return Model(vgg.inputs, outputs_dict) def train (img_content, img_style, img_combination ): extractor = getFeatureExtractor() optimizer = RMSprop() epochs = 8000 for step in range (1 , epochs + 1 ): with tf.GradientTape() as tape: inputs = K.concatenate([img_content, img_style, img_combination], axis=0 ) outputs = extractor(inputs) loss = calc_loss(outputs) grad = tape.gradient(loss, img_combination) optimizer.apply_gradients([(grad, img_combination)]) if step % 1000 == 0 : print ("epoch {}: loss={:.4f}" .format (step, loss)) saveImage(img_combination.numpy()[0 ], './epoch{}.png' .format (step)) fpath_content = '../input/styletransfer/content.jpg' fpath_style = '../input/styletransfer/style.jpg' h, w = cv2.imread(fpath_content, 0 ).shape shape = (w, h) img_content = K.variable(preprocessImage(fpath_content, shape)) img_style = K.variable(preprocessImage(fpath_style, shape)) img_combination = K.variable(preprocessImage(fpath_content, shape)) train(img_content, img_style, img_combination)