
seq2seq语音识别——LAS
LAS的提出
语音识别的研究中端到端的模型正在逐渐取代将声学(acoustic)、发音(pronunciation)和语言(language)模型分别单独训练的方法
端到端的模型主要有两中,一种是CTC,另一种是带有Attention机制的seq2seq
CTC的局限在于其假设输出label是相互条件独立的,而seq2seq则还没有端到端的语音识别
LAS(Attend Listen and Spell)是首个将带Attention的seq2seq应用于端到端的语音识别模型
模型结构
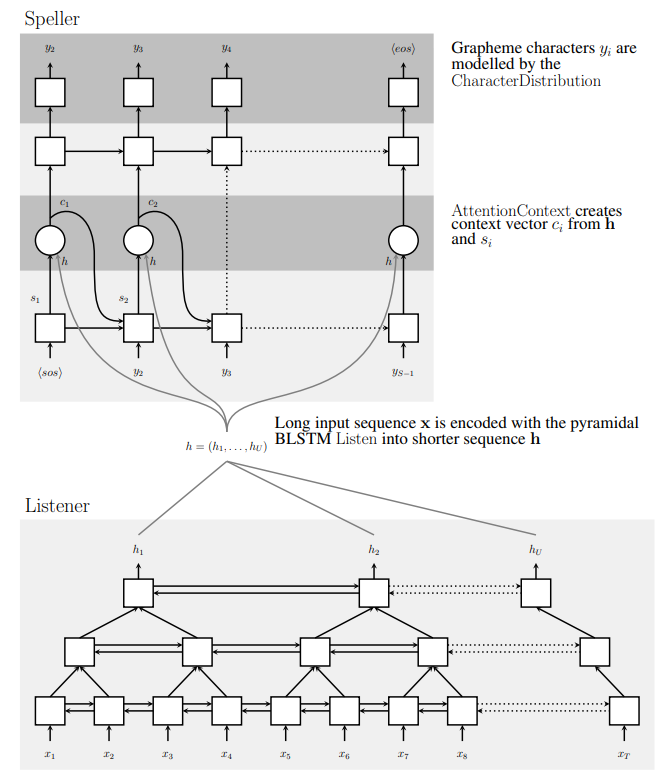
LAS中的Encoder称为Listener,Decoder称为Speller,其结构如图所示
Listener是金字塔型双向LSTM(pyramid BLSTM)
每一层通过将相邻timestep输出concat成一个向量使序列长度减半(个人认为也可以通过1D池化达到相同效果)
金字塔型LSTM的作用是减少Attention的计算量,加速收敛
Speller与普通的带Attention的seq2seq Decoder完全一样
这里贴一下金字塔型RNN序列减半的keras实现
LAS完整代码可以看我的github仓库LAS.py
1 | class ConsecutiveConcat(Layer): |
总的来说LAS没啥特别的亮点,就是普通的seq2seq
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.