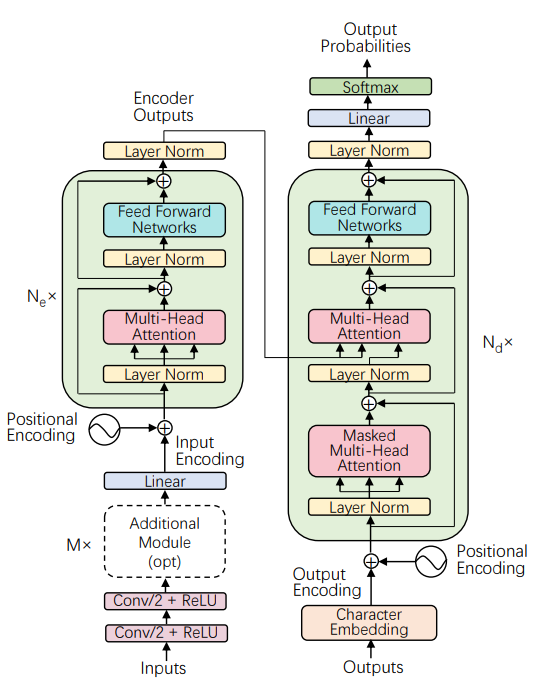
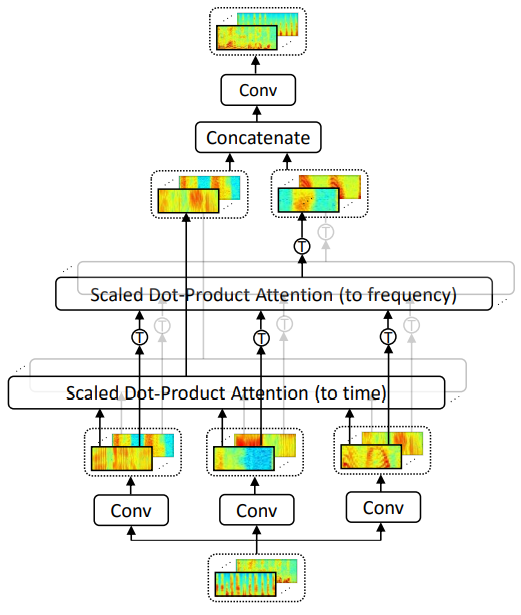
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| class MultiHeadAttention2D(Layer):
def __init__(self, num_heads):
"""A simple implementation of 2D Multi-Head Attention proposed in paper
"Speech-Transformer——A No-Recurrence Sequence-to-Sequence Model for Speech Recognition"
Note that the MultiHeadAttention2D can only be used as self-attention,
since it contains a transpose operation in "frequency attention"
Argument:
:param num_heads: number of attention heads, i.e. number of filters of convolution
"""
super().__init__()
self.num_heads = num_heads
self.conv_Q = Conv2D(num_heads, 5, padding='same')
self.conv_V = Conv2D(num_heads, 5, padding='same')
self.conv_K = Conv2D(num_heads, 5, padding='same')
self.conv_out = Conv2D(1, 5, padding='same')
def call(self, query, value, key=None):
"""
:param query: Query Tensor of shape (batch_size, Tq, dim)
:param value: Value Tensor of shape (batch_size, Tv, dim)
:param key: Key Tensor of shape (batch_size, Tv, dim). If not
given, will use 'value' for both 'key' and 'value'
"""
if not key:
key = value
query = K.expand_dims(query, axis=-1)
value = K.expand_dims(value, axis=-1)
key = K.expand_dims(key, axis=-1)
feat_Q = self.conv_Q(query)
feat_V = self.conv_V(value)
feat_K = self.conv_K(key)
combined = [
(feat_Q[:, :, :, i], feat_V[:, :, :, i], feat_K[:, :, :, i])
for i in range(self.num_heads)
]
combined_transpose = [
(K.permute_dimensions(feat_query, (0, 2, 1)),
K.permute_dimensions(feat_value, (0, 2, 1)),
K.permute_dimensions(feat_key, (0, 2, 1)))
for feat_query, feat_value, feat_key in combined
]
out_temporal_atten = [
Attention()([feat_query, feat_value, feat_key])
for feat_query, feat_value, feat_key in combined
]
out_frequncy_atten = [
Attention()([feat_query_trans, feat_value_trans, feat_key_trans])
for feat_query_trans, feat_value_trans, feat_key_trans in combined_transpose
]
feat_time = K.concatenate([K.expand_dims(feat, -1) for feat in out_temporal_atten], axis=-1)
feat_freq = K.concatenate([K.expand_dims(feat, -1) for feat in out_frequncy_atten], axis=-1)
feat = K.concatenate([feat_time, K.permute_dimensions(feat_freq, (0, 2, 1, 3))], axis=-1)
outputs = self.conv_out(feat)
outputs = K.squeeze(outputs, axis=-1)
return outputs
|