
预训练语言模型GPT
论文链接:
GPT: Improving Language Understanding by Generative Pre-Training
GPT-2:Language Models are Unsupervised Multitask Learners
GPT-3:Language Models are Few-Shot Learners
GPT-2和GPT-3都主要是增大了模型规模,下面讲解的是原GPT论文
GPT实现只需要稍微修改Transformer的代码,下面不贴代码了,可以到我的GitHub看GPT.py
GPT是第一个取得显著成功的学习高层次语义特征的预训练语言模型
此前的预训练语言模型一般都是单词级的,即预训练词嵌入,再设计任务特定的网络结构
而GPT在预训练之后则只用引入较少参数来适应特定任务(往往只有一个全连接分类层)
此外以往的预训练模型往往采用RNN,使得预测范围很小
而GPT选择使用Transformer Decoder结构避免了这种问题
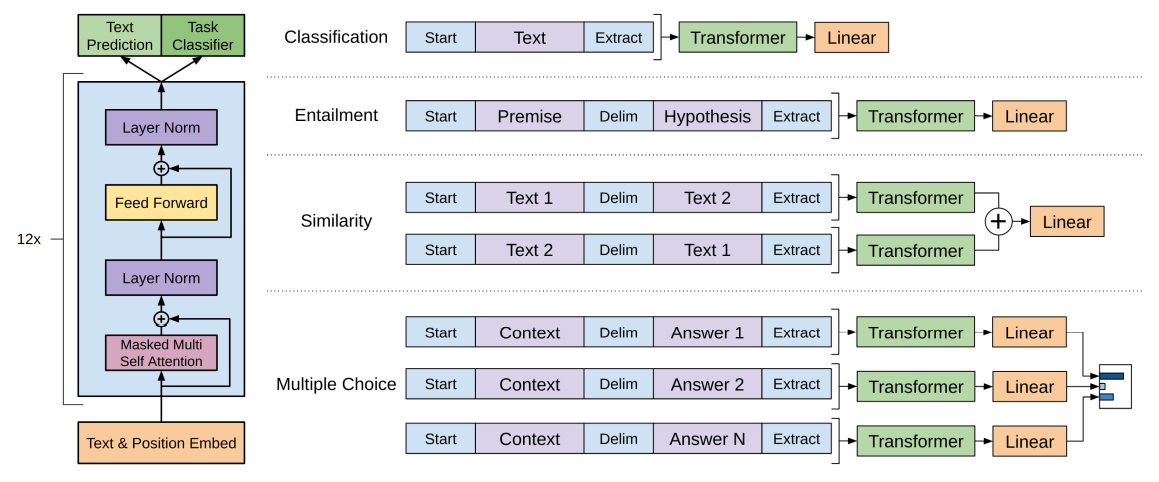
GPT是多个Transformer Block堆叠的结构,每个Block的Attention层使用了Future Mask,但是没有原本decoder中的第二层(计算encoder输出的)Attention
预训练阶段GPT的任务就是简单的句子预测
即输入token序列$U={u1,…,u_n}$,loss为$L_1(U)=\sum_i \log P(u_i|u{i-k,…,u_{i-1}};\theta)$
微调阶段GPT只需要在最后一个timestep的输出上添加一个全连接层用于任务特定的分类即可,最终loss可以加入辅助的句子预测加速收敛
如上图所示,如果微调阶段的输入是句子对,只需要将句子对拼接起来,并加入起始token [start]、结束token [extract]和分隔token [delim]即可