双向预训练语言模型BERT详解
BERT的提出
在之前的研究中,预训练语言模型已被证明对各类NLP问题都十分有效
然而BERT作者认为已有的技术仍然限制了预训练的效果,因为他们都是单向的
例如GPT,使用了Transformer Decoder,其中的future mask使得它只能单向,且预训练任务也只是简单的句子生成
以及ELMo,只是简单的将独立训练的left-to-right和right-to-left模型拼接在一起
因此作者提出了BERT(Bidirectional Encoder Representations from Transformers)
利用Transformer Encoder以及MLM和NSP任务实现在于训练中学得双向的语言表达
论文链接:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT MLM任务的简单实现 BERT_MLM.py
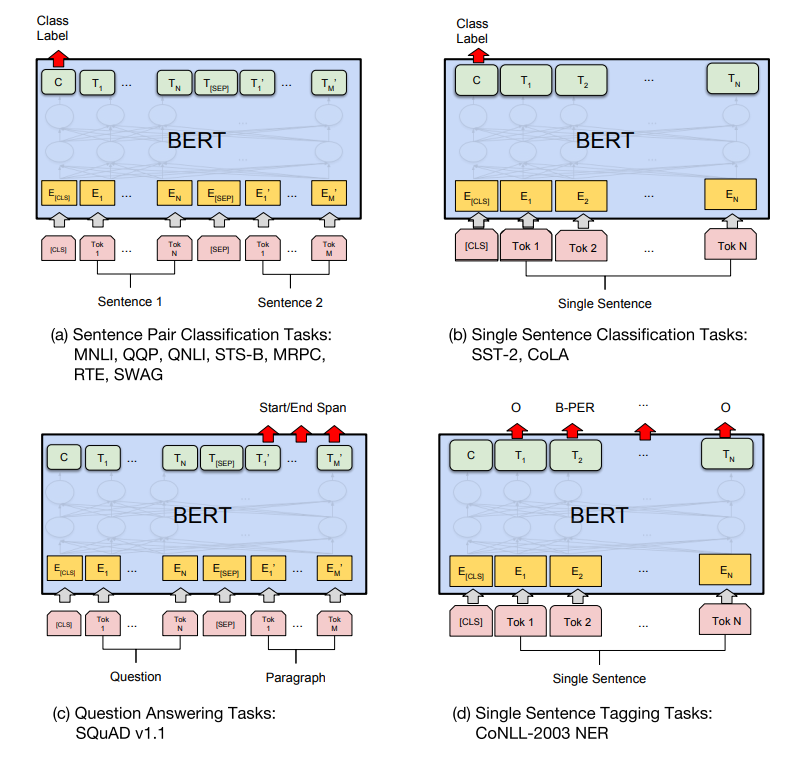
BERT结构
bert结构十分简单,就是多个Transformer Encoder块的堆叠
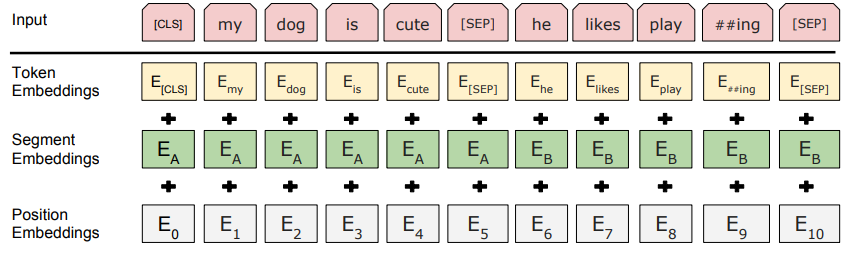
如果输入是句子对(A, B),那么将两个句子拼接在一起并用特殊[SEP] token分隔
所有输入的token序列最前端加入[CLS] token
记[CLS]对应timestep输出的向量为C,其余timestep对应输出分别为$T_1, T_2, …, T_n$(若为句子对则第二个句子输出为$T’_1, T’_2, …, T’_n$)
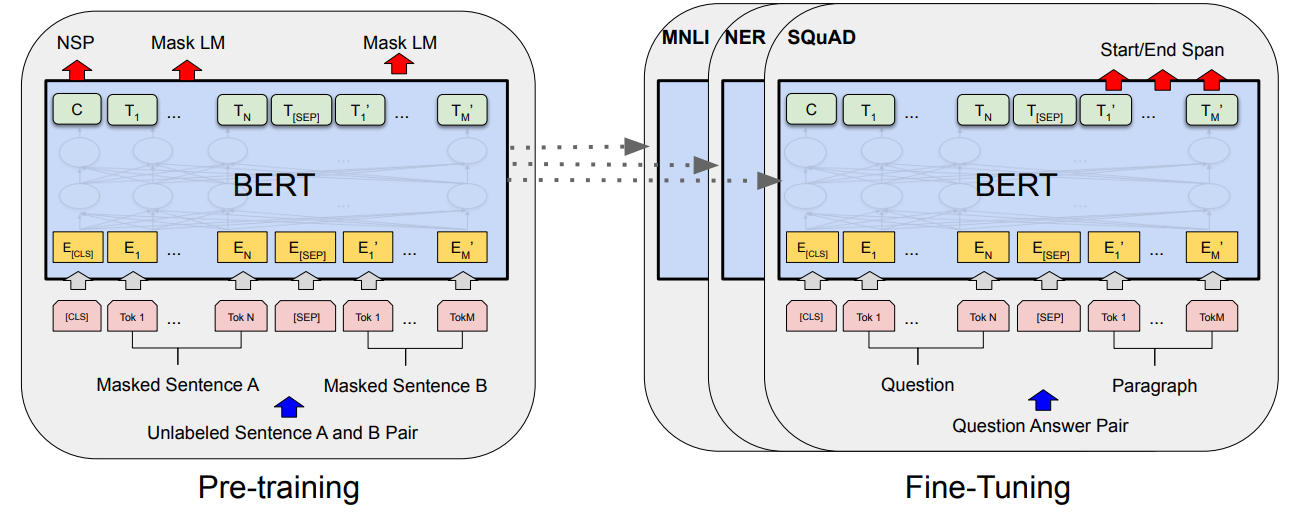
Pre-training
MLM
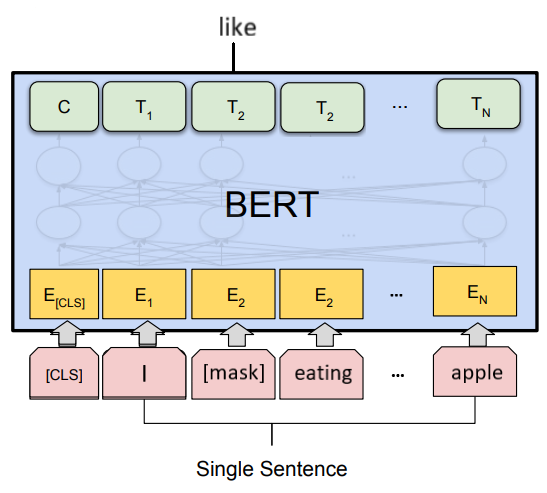
由于标准的条件语言模型只能从左至右或从右至左训练,为了使用Transformer Encoder学得双向表达,作者设计了一种新的训练任务MLM(Mask Language Model)
MLM即随机mask一部分输入token,然后由模型预测这些被mask的token
注意模型只预测被mask的部分,而不是预测整个句子
作者在实验中选择mask掉15%的输入token,其中80%用特殊的[MASK] token代替,10%用一个随机token代替,10%保持不变,此外句子开头添加特殊的[CLS] token
由于模型只预测15%的token,也即只有15%的loss进行反向传播,所以MLM任务收敛比较慢,但最终效果是非常强的
这里贴一下数据预处理的代码,其中输入word_seq是已索引化的token序列,尺寸为(samples, max_length),完整代码可以看我的github仓库
1 | class PretrainBERT: |
NSP
对于一些需要输入句子对的NLP任务,比如QA、NLI等,MLM无法学得句子间的关系,因此作者还提出了NSP(Next Sentence Prediction)任务
对于输入的每一个句子对(A, B),其中50%的B是A的下一个句子,50%的B是随机选择的句子,模型的任务即对B是否是下一个句子进行二分类
二分类的输出概率由向量C计算
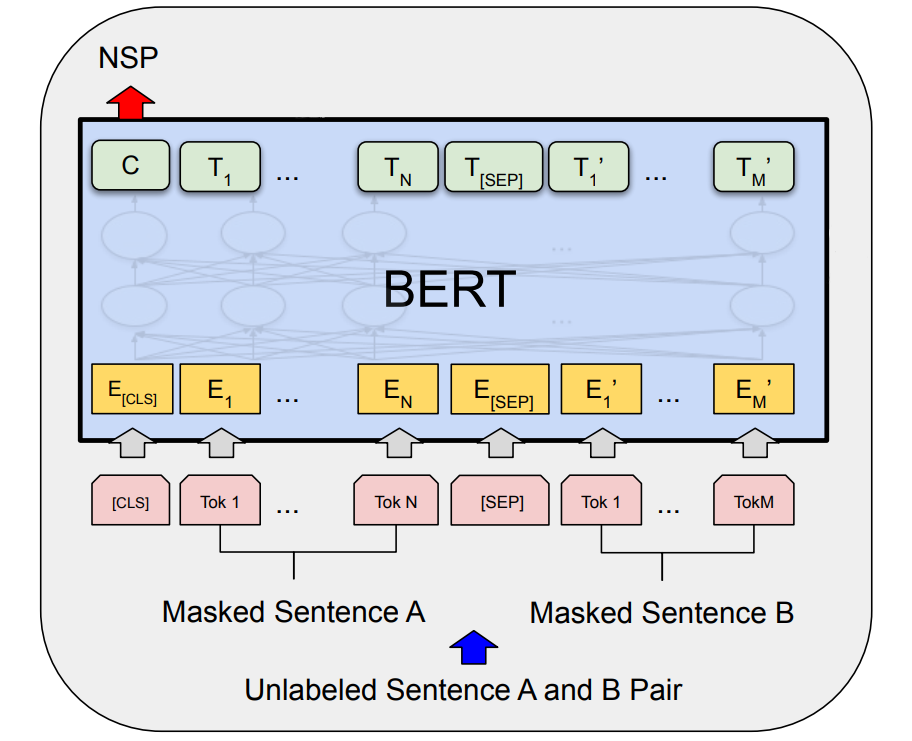
此外为了区分两个句子,除了position embedding和token embedding,还需要加入segment embedding
Fine-tuning
GLUE
GLUE(General Language Understanding Evaluation)包含了九种不同的数据集,简单介绍一下
- MNLI / MRPC:预测句子对的包含、矛盾或中立关系(三分类)
- QQP / MRPC:句子对语义是否相似的二分类任务
- QNLI:判断question-sentence对中sentence是否包含正确答案的二分类任务
- SST-2:单句子情感二分类
- CoLA:单句子语法正确性二分类
- STS-B:句子对语义相似性多分类(5类)
- WNLI:句子对相似性二分类(GLUE官方称该数据集有问题)
BERT在这些任务上的fine-tuning都是在C向量上添加一个全连接层进行分类
SQuAD
SQuAD( Stanford Question Answering Dataset)是一个阅读理解问答对数据集
给定一个question、一段passage和一个answering,目标是在passage中找到answer的范围(text span)
BERT在此数据集上的fine-tuning将question和passage分别作为句子A、B拼接在一起作为输入
在句子B对应timestep的输出上分别添加输出单元为1全连接层,表示每个位置作为answer开头的概率,同理用相同方法表示每个位置作为answer结尾的概率
最后选择开头概率和结尾概率最大的两个位置就确定了text span
SWAG
SWAG(Situations With Adversarial Generations)是一个句子续写数据集,给定一个句子A,目标是从四个句子中选择最适合作为A的续写的句子
fine-tuning的方法是将四个候选句子B分别于句子A拼接,按照前述方法进行二分类