word2vec文本向量化
word2vec
word2vec是一种基于推理的文本向量化技术
它的原理基于分布式假设,即某个单词的含义由文本中在它周围的单词形成
例如“drink”周围总是有“juice”, “beer”等饮料出现,而”guzzle”也是如此
因此可以推测“drink”和”guzzle”是近义词
同时word2vec是基于神经网络学习文本向量表达的技术
相较于基于计数的文本向量化方法,它可以通过mini-batch轻松的处理大语料库
CBOW
CBOW原理
CBOW全称为continuous bag-of-word,是word2vec论文中给出的模型之一
CBOW是一个通过上下文预测目标词的模型
例如,设语料库为“you drink tea and I drink coffee”
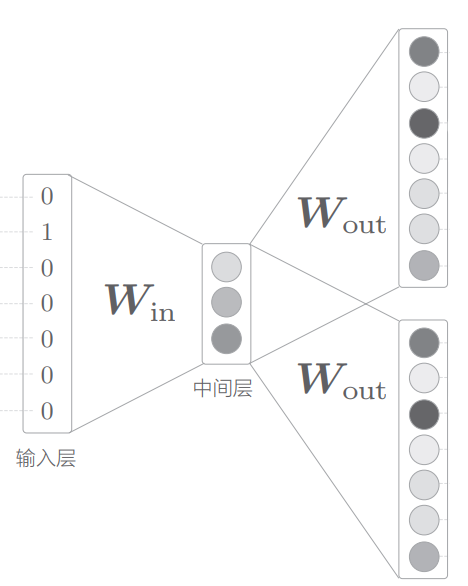
以上下文输入量各为1为例,对网络输入[“you”, “tea”],我们希望它输出”drink”
为了完成这一任务,我们先对语料库建立索引,并对单词one-hot编码
如图所示,对网络输入为上下文单词的one-hot编码,输出为对预料库每个词的预测概率(softmax激活),也即转化为了分类学习任务
网络中两个$W_{in}$是相同的全连接权重矩阵,中间层是各输入的平均
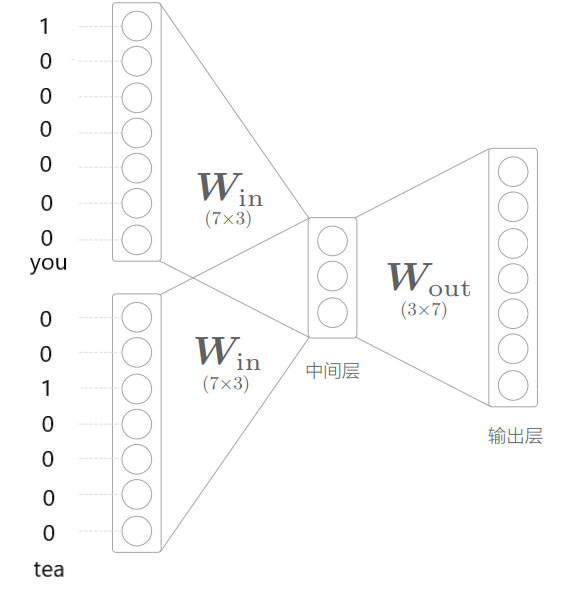
模型训练完之后,权重矩阵 $W{in}$ 的每一行就是一个学得的单词向量
同理,也可以选择$W{out}$的每一列作为学到的向量
显然,每个获得的单词向量维度与中间层维度相同
引入Embedding层
上述的CBOW模型仍然存在一个问题,即对于大规模语料库计算时间无法承受
如果语料库有100万个单词,那么one-hot编码也会有100万维,全连接层和softmax都会出现计算瓶颈
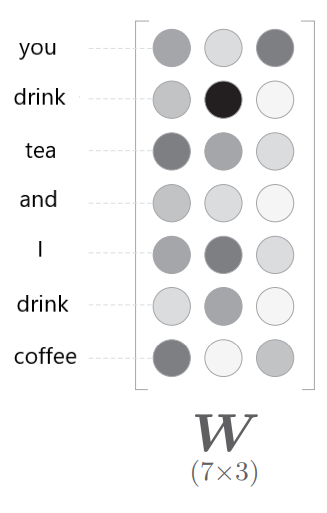
首先考虑$Win$与输入相乘的部分
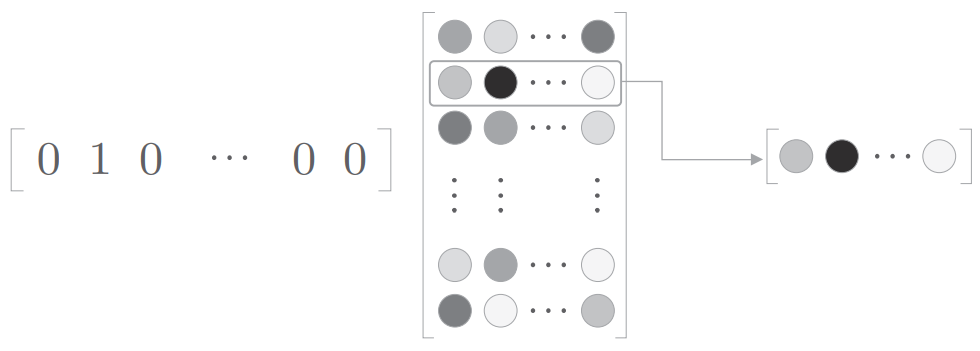
注意到因为输入时one-hot编码,所以这里矩阵乘法本质上就是根据单词id选取 $W{in}$ 某的一行
所以只需要实现一种层,输入一个整数,根据该整数取出矩阵对应的一行即可
我们把这种层称为Embedding层
引入Negative Sampling
解决$W_{out}$和softmax计算瓶颈的思想是用二分类替代多分类
例如对于输入[“you”, “tea”],若我们只输出对于单词”drink”的预测概率
那么$W{out}$处的矩阵乘法本质上就是提取 $W{out}$ 某一列与中间层输出做点积
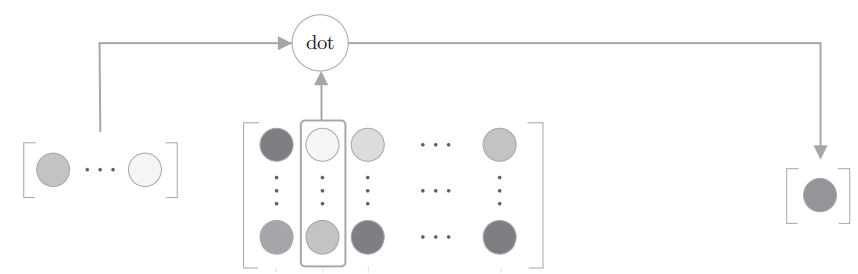
根据这个原理,我们需要提取 $W_{out}$ 正例的列和若干个负例的列
做若干次二分类并计算平均交叉熵损失,由此就解决了多分类的计算瓶颈
这种方法称为Negative Sampling
一般负例的采样对语料库中出现频率高的单词有更高的采样概率
skip-gram
skip-gram是word2vec论文中出现的另一个模型
skip-gram就是将CBOW模型反过来,用目标单词预测上下文,单词向量也从权重矩阵$W$中获得
相同的embedding层、Negative Sampling优化也可用于skip-gram
实际中skip-gram往往比CBOW表现更好(感性上理解是因为预测上下文的任务更难?)