
一些经典的CNN分类网络
LeNet-5
LeNet-5由LeCun于1998年提出,是最早的卷积神经网络之一
LeNet-5虽然结构十分简单,论文阐述的理论在现在看来也大都很基础
但在当时他第一次展示出了依赖自动学习的模式识别系统的潜力,可以说是打开深度学习大门的人之一
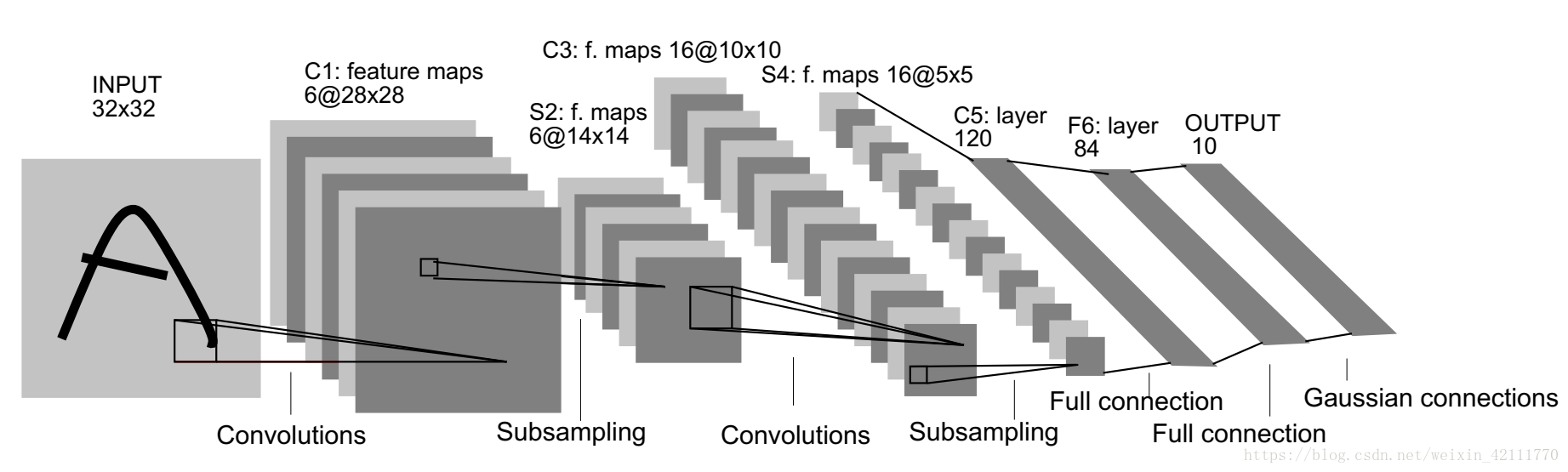
网络总共只有五层(不包括无参数的池化层),依次为
conv1——filter: 6, kernel_size: 5x5
averagePooling——size:2
conv2——filter: 16, kernel_size: 5x5
averagePooling——size:2
FC3——120
FC4——84
OUT5——10
其中除最后一层外,激活函数均为tanh
最后一层不是普通全连接层,而是径向基函数(RBF)
下面用keras写一个稍微化简的Lenet-5,最后一层就用普通的全连接+softmax
1 | def buildNet(): |
AlexNet
论文链接:ImageNet Classification with Deep Convolutional Neural Networks
LeNet在图像分类上虽然十分成功,但受限于当时的硬件条件,这个成果并没有受到太大关注
直到AlexNet在2012年ImageNet竞赛中以远超第二名的成绩夺冠,深度学习才开始有了广泛影响
AlexNet的训练(受限于显存)使用了两张GPU,所以论文中的结构图看起来比较复杂
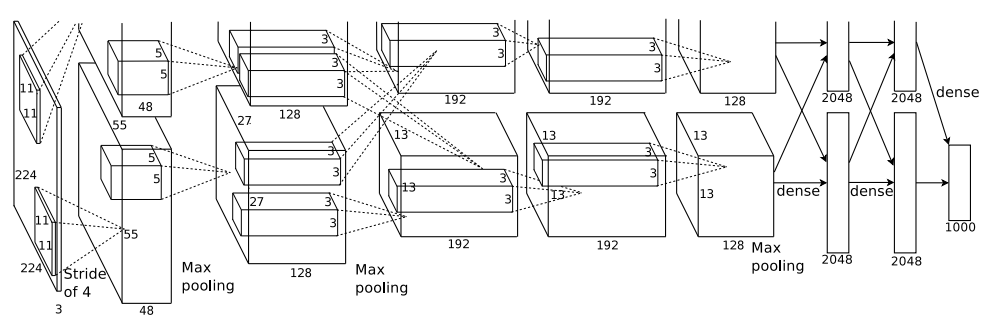
其实可以等价为下图
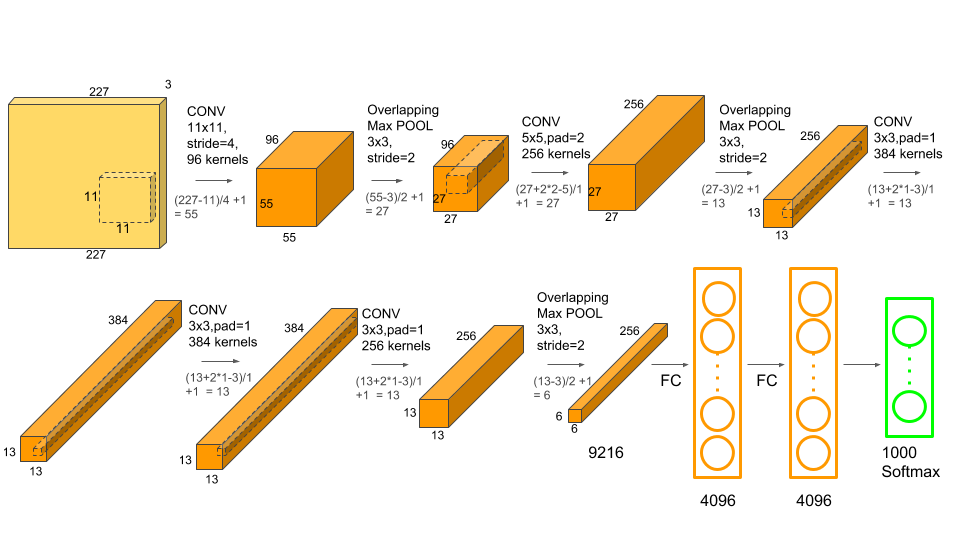
Alexnet的基本结构和LeNet是相同的
即不断增加滤波器数量并缩小特征图尺寸,最后一维展开经过多个全连接层并softmax输出
但AlexNet也用到了许多新技术,例如
- 使用ReLU替代了Tanh和Sigmoid激活,解决了深度网络的梯度消失问题并提高了训练效率
- 使用最大池化代替了此前CNN常用的平均池化,并提出了重叠池化(overlapping pooling),即池化步长小于池化窗口尺寸
- 数据增强以提高模型泛化能力,主要是将原始256x256图像随机地裁剪至224x224,并随机应用水平翻转,其次还有PCA处理和添加随机噪声等
- 训练中使用了DropOut,随机丢弃一部分神经元以避免过拟合
- 提出了局部响应归一化LRN
(注意LRN现已被证明并没有作用,因而大多深度学习框架都没有这个层,BatchNormalization会是较好的选择)
AlexNet凭借加深地网络和这些新技术获得了top-1、top-5 error rates分别37.5%和17%的好成绩
VGG
论文链接:Very Deep Convolutional Networks For Large-Scale Image Recognition
收到AlexNet的影响,此后CNN分类问题中产生了大量十分有价值的模型
最具代表性的就是ImageNet 2014中获得第二名的VGG和第一名的GoogLeNet
论文中作者列出了包含不同层数的VGG结构表,现在比较常用的是VGG16和VGG19
VGG16的结构如下图所示
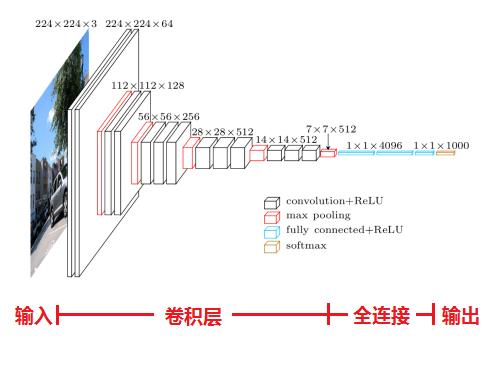
VGG相较于AlexNet的改进主要体现在小卷积核的应用上
整个VGG中作者只使用了3x3和1x1卷积核
作者认为使用两层3x3卷积能获得5x5的感受野,而三层3x3卷积能获得7x7的感受野
若使用两层3x3卷积替代5x5卷积,网络的参数学习量将大大减少
得益于参数量减少,网络就可以在深度和宽度上增加更多
VGG也因此验证了更深的神经网络带来的性能提升
VGG虽然是当年ImageNet的第二名
但它比第一名GoogLeNet迁移学习能力更强,结构也更简单,因此比GoogLeNet更常见
keras中已内置了VGG16和VGG19的预训练模型
1 | def BuildNet(): |
GoogLeNet
Going Deeper with Convolutions
ImageNet 2014中的冠军模型,它的特点体现在Inception结构上
(GoogLeNet名字里前一个L也是大写,是为了致敬LeNet)
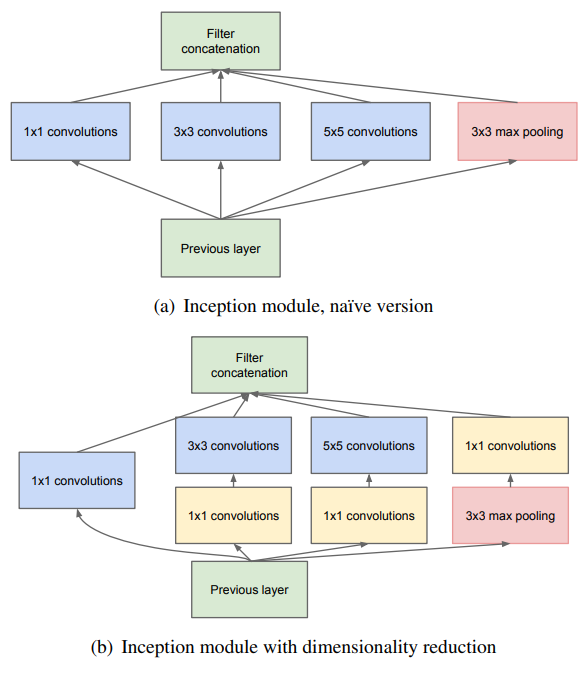
Inception和之前的模型相比最大的不同是使用多个不同尺寸的卷积核提取特征,它的作用有
- 直观上从不同尺度提取的特征更加丰富
- 将稀疏矩阵分解成密集矩阵进行计算加速收敛
将稀疏矩阵密集化是论文中着重说明的一点,可以这样理解:
传统的CNN在某个block的输出特征图中,所有输出特征均匀的分布在3×3尺度上
但Inception结构使得输出特征不再均匀分布,而是不同尺度上相关性强的特征聚集在一起
Inception结构还有一个特点即1×1卷积核的使用,它的作用有
- 在相同感受野下加深网络深度(原理来自Network in Network)
- Inception块中先降维,减少3×3和5×5卷积的计算量
原始GoogLeNet之后又有多篇讨论Inception的论文,提出了Inception V2 / V3等