Pytorch Pytorch和Tensorflow是两个在深度学习领域占绝对主流地位的框架
线性回归 线性回归即在二维平面上给定若干个点,求解其线性关系
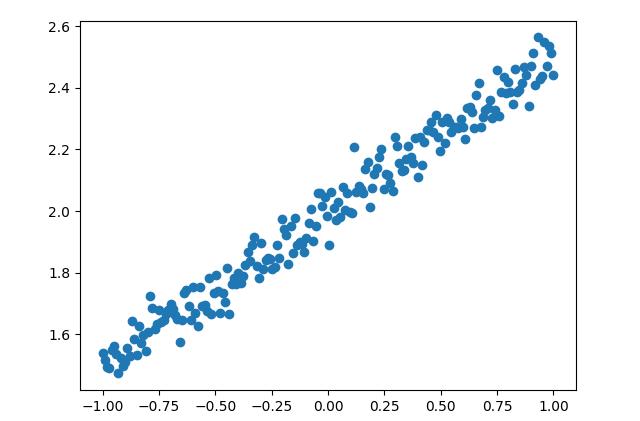
构造数据集 首先利用numpy构造数据集,可视化如下图所示
1 2 3 4 5 6 7 8 9 10 def createData (): X = np.linspace(-1 , 1 , 200 ) np.random.shuffle(X) Y = 0.5 * X + 2 + np.random.normal(0 , 0.05 , (200 ,)) X = np.expand_dims(X, 1 ) Y = np.expand_dims(Y, 1 ) return X, Y X, Y = createData()
然后将numpy对象转换为pytorch运算所要求的Tensor(张量)对象
1 2 3 4 5 import torchX_ten = torch.from_numpy(X).to(torch.float32) Y_ten = torch.from_numpy(Y).to(torch.float32)
网络搭建 我们已知线性回归的目标函数形如$y=wx+b$只需要输入层和输出层各一个神经元
pytorch搭建网络需要构造一个继承torch.nn.Module的类覆写forward方法 定义自己的前向传播
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import torchimport torch.nn as nn''' 网络对象,需继承torch.nn.Module''' class Regressor (torch.nn.Module): def __init__ (self ): super ().__init__() '''定义网络需要的层''' self.layer = nn.Linear(1 , 1 ) '''定义前向传播''' def forward (self, input ): output = self.layer(input ) return output regressor = Regressor()
搭建好网络后定义optimizer和损失函数
1 2 3 4 5 6 from torch.optim import SGDimport torch.nn as nnoptimizer = SGD(regressor.parameters(), lr=0.2 ) loss_func = nn.MSELoss()
网络训练与测试 之后开始训练网络(此处没有使用mini-batch学习)
1 2 3 4 5 6 7 8 for _ in range (100 ): pred = regressor(X_ten) loss = loss_func(pred, Y_ten) optimizer.zero_grad() loss.backward() optimizer.step()
接下来可以看看网络训练的效果了
1 2 3 4 5 6 7 w = regressor.state_dict()['layer.weight' ] b = regressor.state_dict()['layer.bias' ] Y_pred = w * X + b
或者直接进行一次前向传播破坏计算图 ,pytorch禁止了这种做法将tensor强制剥离计算图 ,注意剥离后内存仍指向原址
1 2 Y_pred = regressor(X_ten) Y_pred = Y_pred.detach().numpy()
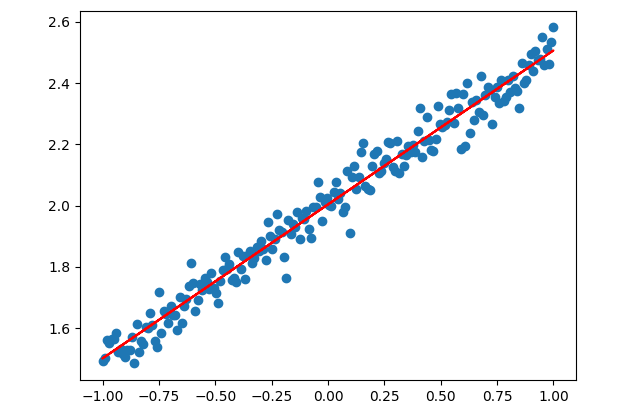
最后进行结果可视化
1 2 3 4 plt.scatter(X, Y) plt.plot(X, Y_pred, color='red' ) plt.show()
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import numpy as npimport matplotlib.pyplot as pltimport torchimport torch.nn as nnfrom torch.optim import SGDdef createData (): X = np.linspace(-1 , 1 , 200 ) np.random.shuffle(X) Y = 0.5 * X + 2 + np.random.normal(0 , 0.05 , (200 ,)) X = np.expand_dims(X, 1 ) Y = np.expand_dims(Y, 1 ) return X, Y '''定义网络''' class Regressor (torch.nn.Module): def __init__ (self ): super ().__init__() '''定义网络需要的层''' self.layer = nn.Linear(1 , 1 ) '''定义前向传播''' def forward (self, input ): output = self.layer(input ) return output X, Y = createData() X_ten = torch.from_numpy(X).to(torch.float32) Y_ten = torch.from_numpy(Y).to(torch.float32) regressor = Regressor() optimizer = SGD(regressor.parameters(), lr=0.2 ) loss_func = nn.MSELoss() '''训练''' for _ in range (100 ): pred = regressor(X_ten) loss = loss_func(pred, Y_ten) optimizer.zero_grad() loss.backward() optimizer.step() '''获取训练后的网络参数''' w = regressor.state_dict()['layer.weight' ] b = regressor.state_dict()['layer.bias' ] Y_pred = w * X + b plt.scatter(X, Y) plt.plot(X, Y_pred, color='red' ) plt.show()
分类 获取Mnist数据集及预处理 mnist是一个经典的手写数字图像数据集,torchvision已内置了mnist
调用torchvision内置的mnist时可同时作一系列预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import torch.utils.data as Dataimport torchvisiondef getData (): data_train = torchvision.datasets.MNIST( root='./data/' , train=True , transform=torchvision.transforms.ToTensor(), download=True , ) data_test = torchvision.datasets.MNIST(root='./data/' , train=False ) return data_train, data_test data_train, data_test = getData() loader = Data.DataLoader(dataset=data_train, batch_size=32 , shuffle=True )
网络搭建 这里使用了pytorch的nn.Sequential类搭建网络,也即顺序模型层的传参顺序 执行
网络中第一个全连接层后使用了relu激活输出层神经元有十个 是因为分类任务需要输出one-hot编码 标签
同时这里使用了一个新的optimizer,名称为Adam
因为是多分类 任务,loss函数使用了交叉熵损失 one-hot编码 ,且网络最后一层要有softmax激活
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import torchimport torch.nn as nnfrom torch.optim import Adamclass Classifier (nn.Module): def __init__ (self ): super ().__init__() self.model = nn.Sequential( nn.Flatten(), nn.Linear(784 , 32 ), nn.ReLU(), nn.Linear(32 , 10 ) ) '''定义前向传播''' def forward (self, input ): output = self.model(input ) return output classifier = Classifier() optimizer = Adam(classifier.parameters(), lr=1e-3 ) loss_func = nn.CrossEntropyLoss()
网络训练与测试 和线性回归的例子不同,这里由于数据量大而采用了mini-batch学习
1 2 3 4 5 6 7 8 9 for epoch in range (1 ): for step, (X, Y) in enumerate (loader): pred = classifier(X) loss = loss_func(pred, Y) optimizer.zero_grad() loss.backward() optimizer.step() print ('Epoch:' , epoch+1 , ' Step:' , step, ' loss:' , loss.item())
最后验证网络效果
1 2 test_X = torch.unsqueeze(data_test.data, dim=1 ).type (torch.float32) / 255. test_Y = data_test.targets
然后测试
1 2 3 4 5 output = classifier(test_X) label_pred = torch.argmax(output, dim=1 ) print ('accuracy:' , np.sum ((test_Y==label_pred).tolist()) / test_Y.shape[0 ])
启动GPU加速 随着数据量越来越大,CPU计算神经网络会越来越吃力
1 2 3 4 5 cuda_on = torch.cuda.is_available() if cuda_on: classifier.cuda() loss_func.cuda()
1 2 3 4 5 6 7 8 9 10 11 12 13 for epoch in range (1 ): for step, (X, Y) in enumerate (loader): if cuda_on: X = X.cuda() Y = Y.cuda() pred = classifier(X) loss = loss_func(pred, Y) optimizer.zero_grad() loss.backward() optimizer.step() print ('Epoch:' , epoch+1 , ' Step:' , step, ' loss:' , loss.item())
1 2 3 if cuda_on: test_X = test_X.cuda() test_Y = test_Y.cuda()
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 import torchimport torch.nn as nnfrom torch.optim import Adamimport torch.utils.data as Dataimport torchvisionimport numpy as npclass Classifier (nn.Module): def __init__ (self ): super ().__init__() self.model = nn.Sequential( nn.Flatten(), nn.Linear(784 , 32 ), nn.ReLU(), nn.Linear(32 , 10 ) ) '''定义前向传播''' def forward (self, input ): output = self.model(input ) return output def getData (): data_train = torchvision.datasets.MNIST( root='./data/' , train=True , transform=torchvision.transforms.ToTensor(), download=True , ) data_test = torchvision.datasets.MNIST(root='./data/' , train=False ) return data_train, data_test cuda_on = torch.cuda.is_available() classifier = Classifier() optimizer = Adam(classifier.parameters(), lr=1e-3 ) loss_func = nn.CrossEntropyLoss() if cuda_on: classifier.cuda() loss_func.cuda() data_train, data_test = getData() loader = Data.DataLoader(dataset=data_train, batch_size=32 , shuffle=True ) for epoch in range (1 ): for step, (X, Y) in enumerate (loader): if cuda_on: X = X.cuda() Y = Y.cuda() pred = classifier(X) loss = loss_func(pred, Y) optimizer.zero_grad() loss.backward() optimizer.step() print ('Epoch:' , epoch+1 , ' Step:' , step, ' loss:' , loss.item()) '''测试''' test_X = torch.unsqueeze(data_test.data, dim=1 ).type (torch.float32) / 255. test_Y = data_test.targets if cuda_on: test_X = test_X.cuda() test_Y = test_Y.cuda() output = classifier(test_X) label_pred = torch.argmax(output, dim=1 ) print ('accuracy:' , np.sum ((test_Y==label_pred).tolist()) / test_Y.shape[0 ])
Pytorch的其他常用功能 模型保存
1 2 3 4 5 torch.save(regressor, 'net.pkl' ) torch.save(regressor.state_dict(), 'net_params.pkl' ) regressor = torch.load('net.pkl' ) regressor.load_state_dict('net_params.pkl' )