Keras Keras是一个用纯Python编写的高级神经网络API
因为keras是主流神经网络框架再次封装后的高级API,所以它的最大优点就是编写效率很高
然而同样由于keras是再封装的高层API,它的执行效率难免较低
(注:keras2.3.0将会是最后一个多后端 Keras 主版本,该版本及之后keras已被内置进tensorflow2,keras官方建议使用 import tensorflow.keras 替代import keras)
线性回归 线性回归即在二维平面上给定若干个点,求解其线性关系
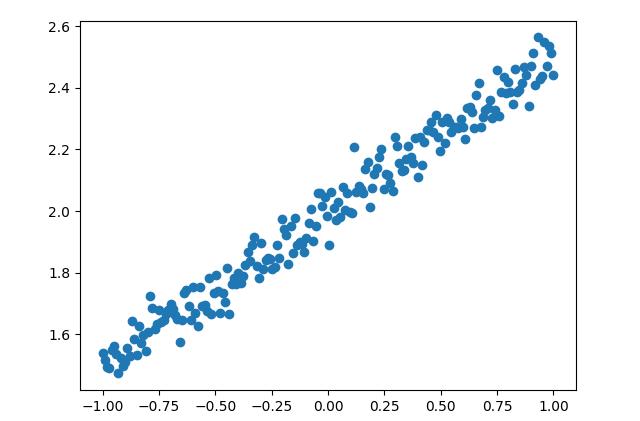
构造数据集 首先利用numpy构造数据集,可视化如下图所示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def createData (): X = np.linspace(-1 , 1 , 200 ) np.random.shuffle(X) Y = 0.5 * X + 2 + np.random.normal(0 , 0.05 , (200 ,)) X = np.expand_dims(X, 1 ) Y = np.expand_dims(Y, 1 ) X_Train, Y_Train = X[:160 ], Y[:160 ] X_Test, Y_Test = X[160 :], Y[160 :] return X_Train, Y_Train, X_Test, Y_Test X_Train, Y_Train, X_Test, Y_Test = createData()
网络搭建 我们已知线性回归的目标函数形如$y=wx+b$只需要输入层和输出层各一个神经元
这里使用了keras的Sequential类搭建网络,也即顺序模型
添加完需要的层之后使用compile指定损失函数和参数更新器,网络就搭建完了
1 2 3 4 5 6 7 8 9 10 11 from keras.models import Sequentialfrom keras.layers import Dense, InputLayermodel = Sequential() model.add(Dense(units=1 , input_shape=(1 ,), name='Dense1' )) model.compile (loss='mse' , optimizer='sgd' )
我们可以查看搭建好的网络信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 print (model.summary())''' Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 1) 2 ================================================================= Total params: 2 Trainable params: 2 Non-trainable params: 0 _________________________________________________________________ None '''
网络训练与测试 keras训练支持直接传入numpy类型数据 ,这是keras方便的一个重要体现
模型的fit方法传入输入输出数据以及batch_size和epoch即可训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 print ("Training..." )hist = model.fit(X_Train, Y_Train, batch_size=40 , epochs=200 , verbose=1 ) print (hist.history['loss' ])''' 训练日志 Training... Epoch 1/200 4/4 [==============================] - 0s 499us/step - loss: 4.3215 Epoch 2/200 4/4 [==============================] - 0s 628us/step - loss: 3.7308 Epoch 3/200 ... Epoch 199/200 4/4 [==============================] - 0s 470us/step - loss: 0.0025 Epoch 200/200 4/4 [==============================] - 0s 498us/step - loss: 0.0025 '''
除此之外keras也支持手动一个batch一个batch的训练
1 2 3 for step in range (301 ): loss = model.train_on_batch(X_Train, Y_Train)
最后是测试
1 2 3 4 5 6 7 8 9 print ("Testing..." )loss = model.evaluate(X_Test, Y_Test, batch_size=40 ) print ("Testing Cost: " ,loss)''' Testing... 1/1 [==============================] - 0s 964us/step - loss: 0.0024 Testing Cost: 0.0023815783206373453 '''
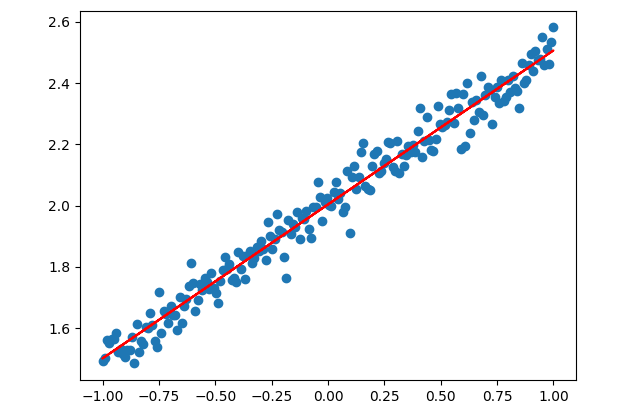
当然我们也可以用get_weights()直接获取网络训练完成后的参数
1 2 3 4 5 6 7 k, b = model.layers[0 ].get_weights() print ("k: {}, b: {}" .format (k,b))Y_Pred = model.predict(X_Test) plt.scatter(X_Test, Y_Test) plt.plot(X_Test, Y_Pred, 'red' ) plt.show()
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import numpy as npfrom keras.models import Sequential from keras.layers import Dense, InputLayerfrom keras.utils import plot_modelimport matplotlib.pyplot as pltdef createData (): X = np.linspace(-1 , 1 , 200 ) np.random.shuffle(X) Y = 0.5 * X + 2 + np.random.normal(0 , 0.05 , (200 ,)) X = np.expand_dims(X, 1 ) Y = np.expand_dims(Y, 1 ) X_Train, Y_Train = X[:160 ], Y[:160 ] X_Test, Y_Test = X[160 :], Y[160 :] return X_Train, Y_Train, X_Test, Y_Test X_Train, Y_Train, X_Test, Y_Test = createData() model = Sequential() model.add(Dense(units=1 , input_shape=(1 ,))) model.compile (loss='mse' , optimizer='sgd' ) print (model.summary())print ("Training..." )hist = model.fit(X_Train, Y_Train, batch_size=40 , epochs=200 , verbose=1 ) print (hist.history['loss' ])print ("Testing..." )cost = model.evaluate(X_Test, Y_Test, batch_size=40 ) print ("Testing Cost: " ,cost)k, b = model.layers[0 ].get_weights() print ("k: {}, b: {}" .format (k,b))Y_Pred = model.predict(X_Test) plt.scatter(X_Test, Y_Test) plt.plot(X_Test, Y_Pred, 'red' ) plt.show()
分类 获取Mnist数据集及预处理 mnist是一个经典的手写数字图像数据集,keras已内置了mnist
由于是分类任务,数据的原始标签需要转换为one-hot编码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from keras.datasets import mnistfrom keras.utils import np_utils(X_train, Y_train), (X_test, Y_test) = mnist.load_data() X_train = X_train.reshape(X_train.shape[0 ], -1 ) / 255 X_test = X_test.reshape(X_test.shape[0 ], -1 ) / 255 Y_train = np_utils.to_categorical(Y_train, num_classes=10 ) Y_test = np_utils.to_categorical(Y_test, num_classes=10 )
网络搭建 同样使用Sequential类,其中第一个全连接层后使用了relu激活输出层神经元有十个 ,且使用了softmax激活
之后optimizer我们实例化了Adam类,并自定义了学习率多分类 任务,loss函数使用了交叉熵损失
注意到compile多了一个metrics,它用来指定一些模型的度量标准,但它不参与网络学习 ,只显示训练情况
1 2 3 4 5 6 7 8 9 10 11 12 13 from keras.models import Sequentialfrom keras.layers import Dense, Activationfrom keras.optimizers import Adammodel = Sequential() model.add(Dense(32 , input_dim=784 )) model.add(Activation('relu' )) model.add(Dense(10 )) model.add(Activation('softmax' )) model.compile (optimizer=Adam(lr=0.002 ), loss='categorical_crossentropy' , metrics=['accuracy' ])
网络训练与测试 这里训练日志多了一个accuracy,就是之前compile指定的metrics
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 print ('Training...' )model.fit(X_train, Y_train, epochs=2 , batch_size=32 , verbose=1 ) print ('Testing...' )loss, accuracy = model.evaluate(X_test, Y_test, batch_size=32 , verbose=1 ) print ('test loss: ' , loss)print ('test accuracy: ' , accuracy)''' Training... Epoch 1/2 1875/1875 [==============================] - 2s 838us/step - loss: 0.3021 - accuracy: 0.9124 Epoch 2/2 1875/1875 [==============================] - 2s 871us/step - loss: 0.1681 - accuracy: 0.9510 Testing... 313/313 [==============================] - 0s 953us/step - loss: 0.1570 - accuracy: 0.9528 test loss: 0.15704774856567383 test accuracy: 0.9527999758720398 '''
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import numpy as npfrom keras.datasets import mnistfrom keras.utils import np_utilsfrom keras.models import Sequentialfrom keras.layers import Dense, Activationfrom keras.optimizers import Adamfrom keras.utils import plot_model(X_train, Y_train), (X_test, Y_test) = mnist.load_data() X_train = X_train.reshape(X_train.shape[0 ], -1 ) / 255 X_test = X_test.reshape(X_test.shape[0 ], -1 ) / 255 Y_train = np_utils.to_categorical(Y_train, num_classes=10 ) Y_test = np_utils.to_categorical(Y_test, num_classes=10 ) model = Sequential() model.add(Dense(32 , input_dim=784 )) model.add(Activation('relu' )) model.add(Dense(10 )) model.add(Activation('softmax' )) model.compile (optimizer=Adam(lr=0.002 ), loss='categorical_crossentropy' , metrics=['accuracy' ]) print ('Training...' )model.fit(X_train, Y_train, epochs=2 , batch_size=32 , verbose=1 ) print ('Testing...' )loss, accuracy = model.evaluate(X_test, Y_test, batch_size=32 , verbose=1 ) print ('test loss: ' , loss)print ('test accuracy: ' , accuracy)
keras的其他常用功能 模型保存
1 2 3 4 5 6 7 from keras.models import load_modelmodel.save('./save/model.h5' ) model.save_weights('./save/model_weights.h5' ) model = load_model('./save/model.h5' ) model.load_weights('./save/model_weights.h5' )
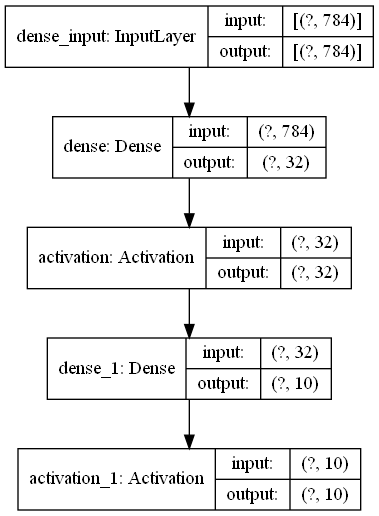
模型可视化,例如刚才的分类网络
1 2 from keras.utils import plot_modelplot_model(model, to_file='model.png' , show_shapes=True )